
FastApi 部署调用
环境准备
本文基础环境如下:
1 | |
本文默认学习者已安装好以上 Pytorch(cuda) 环境,如未安装请自行安装。
首先 pip 换源加速下载并安装依赖包
1 | |
考虑到部分同学配置环境可能会遇到一些问题,我们在AutoDL平台准备了Qwen2.5的环境镜像,点击下方链接并直接创建Autodl示例即可。
https://www.codewithgpu.com/i/datawhalechina/self-llm/Qwen2.5-self-llm
模型下载
使用 modelscope 中的 snapshot_download 函数下载模型,第一个参数为模型名称,参数 cache_dir 为模型的下载路径。
新建 model_download.py 文件并在其中输入以下内容,粘贴代码后请及时保存文件,如下图所示。并运行 python model_download.py 执行下载,模型大小为 15GB,下载模型大概需要 5 分钟。
1 | |
注意:记得修改
cache_dir为你的模型下载路径哦~
代码准备
新建 api.py 文件并在其中输入以下内容,粘贴代码后请及时保存文件。以下代码有很详细的注释,大家如有不理解的地方,欢迎提出 issue 。
1 | |
注意:记得修改
model_name_or_path为你的模型下载路径哦~
Api 部署
在终端输入以下命令启动api服务:
1 | |
加载完毕后出现如下信息说明成功。

默认部署在 6006 端口,通过 POST 方法进行调用,可以使用 curl 调用,如下所示:
1 | |

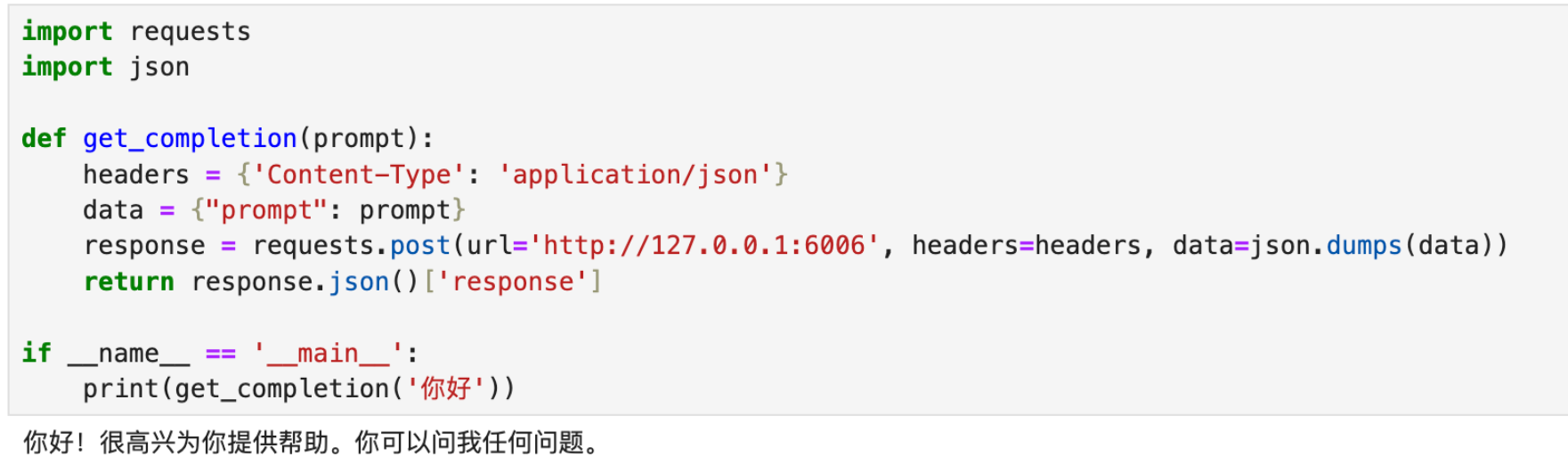
也可以使用 python 中的 requests 库进行调用,如下所示:
1 | |
得到的返回值如下所示:
1 | |
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Hongwei Zhao's Blog!
相关推荐

2025-11-16
Langchain 接入
环境准备本文基础环境如下: 123456----------------ubuntu 22.04python 3.12cuda 12.1pytorch 2.3.0---------------- 本文默认学习者已安装好以上 Pytorch(cuda) 环境,如未安装请自行安装。 pip 换源加速下载并安装依赖包 12345678910# 升级pippython -m pip install --upgrade pip# 更换 pypi 源加速库的安装pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/si...
2025-11-16
WebDemo部署
环境准备123456----------------ubuntu 22.04python 3.12cuda 12.1pytorch 2.3.0---------------- 本文默认学习者已安装好以上 Pytorch(cuda) 环境,如未安装请自行安装。 pip 换源加速下载并安装依赖包 123456789# 升级 pippython -m pip install --upgrade pip# 更换 pypi 源加速库的安装pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simplepip in...

2025-11-16
Lora 微调 SwanLab可视化记录版
本节我们简要介绍基于 transformers、peft 等框架,使用 Qwen2.5-7B-Instruct 模型在中文法律问答数据集 DISC-Law-SFT 上进行Lora微调训练,同时使用 SwanLab 监控训练过程与评估模型效果,并比较0.5B/1.5B/7B/14B模型在此任务上的表现。 Lora 是一种高效微调方法,深入了解其原理可参见博客:知乎|深入浅出 Lora。 训练过程:Qwen2.5-LoRA-Law 目录 SwanLab简介 环境配置 准备数据集 模型下载与加载 集成SwanLab 开始微调(完整代码) 训练结果演示 补充 👋...
2025-11-16
vLLM 部署调用
vLLM 简介vLLM 框架是一个高效的大语言模型推理和部署服务系统,具备以下特性: 高效的内存管理:通过 PagedAttention 算法,vLLM 实现了对 KV 缓存的高效管理,减少了内存浪费,优化了模型的运行效率。 高吞吐量:vLLM 支持异步处理和连续批处理请求,显著提高了模型推理的吞吐量,加速了文本生成和处理速度。 易用性:vLLM 与 HuggingFace 模型无缝集成,支持多种流行的大型语言模型,简化了模型部署和推理的过程。兼容 OpenAI 的 API 服务器。 分布式推理:框架支持在多 GPU 环境中进行分布式推理,通过模型并行策略和高效的数据通信,提升了处理大...

2025-11-16
o1-like 推理链实现
OpenAI o1 model 简介OpenAI o1 系列模型是使用强化学习训练的大语言模型,用于执行复杂推理。o1 模型在回答之前会思考,在向用户做出回应之前可以产生一个长的内部思维链。 o1 模型在科学推理方面表现出色,在编程竞赛(Codeforces)中排名 89%,在美国数学奥林匹克竞赛(AIME)的预选中位列前 500 名,在物理、生物学和化学问题基准测试(GPQA)中超越了人类博士水平。 OpenAI o1 系列模型不仅提高了模型的实用性,还为未来AI技术的发展开辟了新的道路。目前,o1模型包括 o1-preview 和 o1-mini 两个版本,其中 o1-previe...

2025-11-16
Lora 微调
本节我们简要介绍如何基于 transformers、peft 等框架,对 Qwen2.5-7B-Instruct 模型进行 Lora 微调。Lora 是一种高效微调方法,深入了解其原理可参见博客:知乎|深入浅出 Lora。 这个教程会在同目录下给大家提供一个 nodebook 文件,来让大家更好的学习。 环境配置在完成基本环境配置和本地模型部署的情况下,你还需要安装一些第三方库,可以使用以下命令: 123456789101112python -m pip install --upgrade pip# 更换 pypi 源加速库的安装pip config set global.index-u...