
参数估计
统计学与概率论的区别就是归纳和演绎,前者通过样本推测总体的分布,而后者已知总体分布去研究样本。因此参数估计则是归纳的过程,参数估计有两种形式:点估计和区间估计(点估计和区间估计都是对于未知参数的估计,而点估计给出的是一个参数可能的值,区间估计给出的是参数可能在的范围)。
基本概念
- 统计量: 样本中包含着总体的信息, 针对不同要求构造出样本的某种函数, 这种函数在统计学中称统计量。
- 参数空间: 假设总体概率密度函数形式已知,未知分布中的参数$\theta$, $\theta$ 全部可容许值组成的集合称为参数空间, 记为$\Theta$
点估计
点估计的概念
点估计(Point estimation) :设$x_1, …, x_n$ 来自总体的一个样本,用于估计未知参数$\theta$ 统计量$\hat{\theta}=\hat{\theta}(x_1,…,x_n)$ 为$\theta$ 估计量,或称为$\theta$ 点估计。
点估计的方法
矩估计
定义 :设总体概率函数已知,为$p(x;\theta_1,…,\theta_k)$,$(\theta_1,…,\theta_k)\in\Theta$ 未知参数或参数向量,$x_1,…,x_n$ 样本,假定总体的$k$ 原点矩$\mu_k$ 在,则对所有的$j$,$o<j<k$,$\mu_j$ 存在,若假设$\theta_1,…,\theta_k$ 够表示成$\mu_1,…,\mu_k$ 函数$\theta_j=\theta_j(\mu_1,…,\mu_k)$,则可给出诸$\theta_j$ 矩估计:
$$
\hat{\theta_j}=\theta_j(a_1,…,a_k),\quad j=1,…,k
$$
其中$a_1,…,a_k$ 前$k$ 样本原点矩$a_j=\frac{1}{n}\sum_{i=1}^{n}x_i^j$.
矩估计基于大数定律(格里纹科定理),实质是用经验分布函数去替换总体分布,矩估计可以概括为:
用样本矩代替总体矩(可以是原点矩也可以是中心矩);
- 用样本矩的函数去替换相应的总体矩的函数。
注 :矩估计可能是不唯一的,尽量使用低阶矩给出未知参数的估计 。
最大似然估计
定义 :设总体的概率函数为$p(x;\theta),\ \theta\in\Theta$,其中$\theta$ 一个未知参数或几个未知参数组成的参数向量,$\Theta$ 参数空间,$x_1,…,x_n$ 来自该总体的样本,将样本的联合概率函数看成$\theta$ 函数,用$L(\theta;x_1,…,x_n)$ 示,简记为$L(\theta)$,
$$
L(\theta)=L(\theta;x_1,…,x_n)=p(x_1;\theta)p(x_2;\theta)…p(x_n;\theta)
$$
$L(\theta)$ 为样本的似然函数。若统计量$\hat{\theta}=\hat{\theta}(x_1,…,x_n)$ 足
$$
L(\hat{\theta})=\max_{\theta\in\Theta}L(\theta)
$$
则称$\hat{\theta}$ $\theta$ 最大似然估计,简称MLE(maximum likelihood estimate).注 :最大似然估计基于样本观测数据,根据概率论思想进行参数估计,首先抽取一定样本,默认这些样本的出现概率是符合原始分布的,即恰好抽到这些样本是因为这些样本出现的概率极大,然后根据概率密度计算联合概率,形成似然函数,似然函数极值位置即为参数的估计值。最大似然估计的前提是已知数据的分布。
最大似然估计步骤 :
- 写出似然函数;
- 对似然函数取对数,并整理;
- 求参数向量的偏导,令其为0,得到似然方程;
- 求解似然方程,其解为参数值。
最小均方误差估计
在样本量一定时,评价一个点估计好坏的度量指标可使用估计值$\hat{\theta}$ 参数真值$\theta$ 距离函数,最常用的是距离平方,由于$\hat{\theta}$ 有随机性,对该函数求期望即得均方误差:
$$
\begin{align}
MSE(\hat{\theta})&=E(\hat{\theta}-\theta)^2\
&=E[(\hat{\theta}-E\hat{\theta})+(E\hat{\theta}-\theta)]^2\
&=E(\hat{\theta}-E\hat{\theta})^2+(E\hat{\theta}-\theta)^2+\underbrace{2E[(\hat{\theta}-E\hat{\theta})(E\hat{\theta}-\theta)]}{E(\hat{\theta}-E\hat{\theta})=0}\
&=\underbrace{Var(\hat{\theta})}{点估计的方差}+\underbrace{(E\hat{\theta}-\theta)^2}_{偏差的平方}
\end{align}
$$
其中,如果$\hat{\theta}$ $\theta$ 无偏估计,则$MSE(\hat{\theta})=Var(\hat{\theta})$,此时用均方误差评价点估计与用方差是完全一样的。如果如果$\hat{\theta}$ 是$\theta$ 无偏估计,就要看其均方误差$MSE(\hat{\theta})$,即不仅要看其方差大小,还要看其偏差大小。定义 :设有样本$x_1,…,x_n$,对待估参数$\theta$,设有一个估计类,如果对该估计类中另外任意一个$\theta$ 估计$\widetilde{\theta}$,在参数空间$\Theta$ 都有$MSE_\theta(\hat{\theta})\leq MSE_\theta(\widetilde{\theta})$,称$\hat{\theta}(x_1,…,x_n)$ 该估计类中$\theta$ 一致最小均方误差估计。
最小方差无偏估计
定义 :设$\hat{\theta}$ $\theta$ 一个无偏估计,如果对另外任意一个$\theta$ 无偏估计$\widetilde{\theta}$,在参数空间$\Theta={\theta}$ 都有$Var_{\theta}(\hat{\theta})\leq Var_{\theta}(\widetilde{\theta})$,则称$\hat{\theta}$ $\theta$ 一致最小方差无偏估计,简记为UMVUE。
判断准则 :设$\hat{\theta}=\hat{\theta}(x_1,…,x_n)$ $\theta$ 一个无偏估计,$Var(\hat{\theta})<+\infty$.如果对任意一个满足$E(\varphi(x_1,…,x_n))=0$ $\varphi$,都有
$$
Cov_\theta(\hat{\theta},\varphi)=0,\quad\forall\theta\in\Theta,
$$
则$\hat{\theta}$ $\theta$ UMVUE.贝叶斯估计
区别于频率学派,在统计推断中贝叶斯用到了三种信息** :总体信息、样本信息和先验信息**(频率学派只用了前两种),其中:
- 总体信息:总体信息即总体分布或总体所属分布族提供的信息,如,若已知总体是正态分布,则可以知道很多信息;
- 样本信息:样本信息即抽取样本所得观测值提供的信息,如,在有了样本观测值后,可以根据它知道总体的一些特征数;
- 先验信息:若把抽取样本看作做一次试验,则样本信息就是试验中得到的信息,如,在一次抽样后,这第一次的抽样就是先验信息。先验信息来源于经验和历史资料。
回顾贝叶斯公式:设${B_1, B_2, …B_n}$ 样本空间的一个分割,$A$ $\Omega$ 的一个事件,$P(B_i)>0$,$i=1,2,…,n$,$P(A)>0$,则
$$
P(B_i|A)=\frac{P(A|B_i)P(B_i)}{\sum_{j=1}^{n}P(A|B_j)P(B_j)}
$$
贝叶斯密度函数形式 :在参数$\theta$ 布已知(已假设)的情况下,$p(x|\theta)$ 示随机变量$\theta$ 某个给定值时总体的条件概率函数,(参考$P(A|B)$);
任一未知量$\theta$ 可以看作随机变量,可用一个概率分布去描述,这个分布成为先验分布,该先验分布$\pi(\theta)$,(参考$P(B)$);
贝叶斯的观点,样本$X=(x_1,…,x_n)$ 产生需分两步:
- 从先验分布$\pi(\theta)$ 生一个样本$\theta_0$;
- 从$p(X|\theta_0)$ 产生一组样本。
此时,样本$X=(x_1,…,x_n)$ 联合条件概率函数(参考$\sum_{j=1}^{n}P(A|B_j)$)为
$$
p(X|\theta_0)=p(x_1,…,x_n|\theta_0)=\prod^{n}_{i=1}p(x_i|\theta_0)
$$因为$\theta_0$ 知,是从先验分布$\pi(\theta)$ 产生的,所以需要考虑它的发生概率,样本$X$ 参数$\theta$ 联合分布(参考$\sum_{j=1}^{n}P(A|B_j)P(B_j)$)为
$$
h(X,\theta)=p(X|\theta)\pi(\theta)
$$因为目的是对$\theta$ 行推断,所以在有样本观测值$X=(x_1,…,x_n)$ 后,可依据$h(X,\theta)$ $\theta$ 出推断,按照乘法公式(参考1.5.2节),$h(X,\theta)$ 分解为
$$
h(X,\theta)=\pi(\theta|X)m(X)
$$
其中,$m(X)$ $X$ 边际概率函数,类比$\pi(\theta)$,
$$
m(X)=\int_\Theta h(X,\theta)d\theta=\int_\Theta p(X|\theta)\pi(\theta)d\theta
$$
所以可通过条件概率$\pi(\theta|X)$ 断$\theta$ 分布
$$
\pi(\theta|X)=\frac{h(X,\theta)}{m(X)}=\frac{p(X|\theta)\pi(\theta)}{\int_{\Theta}p(X|\theta)\pi(\theta)d\theta}
$$
该分布成为$\theta$ 后验分布。它其实是利用总体和样本对先验分布$\pi(\theta)$ 整的结果,比$\pi(\theta)$ 接近$\theta$ 实际情况(机器学习里的贝叶斯模型就是基于这样的原理)。Flag :感觉贝叶斯定理很有意思,今后也会学习相关的贝叶斯分析数据,敬请期待~
点估计的优良性准则
无偏性 :设$\hat{\theta}=\hat{\theta}(x_1,…,x_n)$ $\theta$ 一个估计,$\theta$ 参数空间为$\Theta$,若对任意的$\theta \in \Theta$,有
$$
E_{\theta}(\hat{\theta})=\theta
$$
则称$\hat{\theta}$ $\theta$ 无偏估计,否则称为有偏估计。无偏性的要求也可以改写为$E_{\theta}(\hat{\theta-\theta})=0$,无偏性表示表示估计参数与真实参数没有系统偏差。一个重要的结论 :样本均值$\bar{x}=\frac{1}{n}\sum_{i=1}^nx_i$ 总体均值$\mu$ 无偏估计。样本方差$s_n^2=\frac{1}{n}\sum_{i=1}^n(x_i-\bar{x})^2$ 是总体方差$\sigma^2$ 无偏估计(而是渐进无偏估计),因此需要对样本方差进行修正,$s^2=\frac{1}{n-1}\sum_{i=1}^n(x_i-\bar{x})^2$.
- 样本均值的无偏性推导
$$
\begin{align}
E(\bar{x})=&E(\frac{1}{n}\sum_{i=1}^nx_i)\
=&\frac{1}{n}\sum_{i=1}^nE(x_i),\ x_i为iid\
=&\frac{1}{n}\sum_{i=1}^n\mu\
=&\mu
\end{align}
$$- 样本方差的有偏性推导
$$
\begin{align}
E(s_n^2)=&E[\frac{1}{n}\sum_{i=1}^n(x_i-\bar{x})^2]\
=&E[\frac{1}{n}\sum_{i=1}^n((x_i-\mu)-\frac{1}{n}(\bar{x}-\mu))^2]\
=&E[\frac{1}{n}\sum_{i=1}^n((x_i-\mu)^2-\frac{2}{n}(x_i-\mu)(\bar{x}-\mu)+\frac{1}{n}(\bar{x}-\mu)^2)]\
=&E[\frac{1}{n}\sum_{i=1}^n(x_i-\mu)^2-\frac{2}{n}\sum_{i=1}^n(x_i-\mu)(\bar{x}-\mu)+(\bar{x}-\mu)^2],\ 其中,\bar{X}-\mu=\frac{1}{n}\sum_{i=1}^n(x_i-\mu)\
=&E[\frac{1}{n}\sum_{i=1}^n(x_i-\mu)^2-2(\bar{x}-\mu)^2+(\bar{x}-\mu)^2]\
=&E[\frac{1}{n}\sum_{i=1}^n(x_i-\mu)^2-(\bar{x}-\mu)^2]\
=&E[\frac{1}{n}\sum_{i=1}^n(x_i-\mu)^2]-E[(\bar{x}-\mu)^2]\
=&\sigma^2-E[(\bar{x}-\mu)^2]\ …(1)\
=&\sigma^2-\frac{\sigma^2}{n}\
=&\frac{n-1}{n}\sigma^2,\quad 当n\rightarrow \infty时, E(s_n^2)\rightarrow \sigma^2\
\
E[(\bar{x}-\mu)^2]=&E(\bar{x}^2)-2\mu E(\bar{x})+\mu^2\
=&E(\bar{x}^2)-\mu^2\
=&Var(\bar{x})+E^2(\bar{x})-\mu^2\
=&Var(x)\
=&\frac{\sigma^2}{n}\ …代入(1)式
\end{align}
$$
有效性
无偏估计往往有很多种,以总体均值为例,$x_1,…,x_n$ 取自某总体的样本,样本均值$\mu$ 样本$x_i$ 是总体均值的无偏估计,对于两个估计参数的选取需要基于一个度量无偏估计优劣的准则。有效性作为这样的准则,反映了参数估计值和参数真值的波动,波动大小可用方差来衡量,波动越小表示参数的估计越有效。
设$\hat{\theta_1}$,$\hat{\theta_2}$ $\theta$ 两个无偏估计,如果对任意的$\theta\in\Theta$
$$
Var(\hat{\theta}_1)\leq Var(\hat{\theta}_2)
$$
且至少有一个$\theta\in\Theta$ 得上述不等号严格成立,则称$\hat{\theta}_1$ $\hat{\theta}_2$ 效。相合性
根据格里纹科定理,随着样本量不断增大,经验分布函数逼近真实分布函数,即设$\theta\in\Theta$ 未知参数,$\hat{\theta}_n=\hat{\theta}n(x_1,…,x_n)$ $\theta$ 一个估计量,$n$ 样本容量,若对任何一个$\epsilon>0$,有
$$
\lim{n\rightarrow\infty}P(|\hat{\theta}_n-\theta|\geq\epsilon)=0
$$
则称$\hat{\theta}_n$ 参数$\theta$ 相合估计。定理1 :设$\hat{\theta}_n=\hat{\theta}n(x_1,…,x_n)$ $\theta$ 一个估计量,若
$$
\lim{n\rightarrow\infty}E(\hat{\theta}n)=\theta,\quad\lim{n\rightarrow\infty}Var(\hat{\theta}_n)=0
$$
则$\hat{\theta}_n$ $\theta$ 相合估计。定理2 :若$\hat{\theta}{n1},…,\hat{\theta}{nk}$ 别是$\theta_1,…,\theta_k$ 相合估计,$\eta=g(\theta_1,…,\theta_k)$ $\theta_1,…,\theta_k$ 连续函数,则$\hat{\eta}n=g(\hat{\theta}{n1},…,\hat{\theta}_{nk})$ $\eta$ 相合估计。
矩估计一般都具有相合性:
- 样本均值是总体均值的相合估计;
- 样本标准差是总体标准差的相合估计;
- 样本变异系数$s/\bar{x}$ 总体变异系数的相合估计。
渐进正态性(MLE)
在很一般条件下,总体分布$p(x;\theta)$ 的$\theta$ MLE$\hat{\theta}_n$ 有相合性和渐进正态性,即$\hat{\theta}n\sim AN(\theta,\frac{1}{nI(\theta)})$,其中$n$ 样本容量,$I(\theta)=\int{-\infty}^{\infty}(\frac{\part{lnp}}{\part\theta})^2p(x;\theta)dx$ 费希尔信息量。
充分性(UMVUE)
- 任一参数$\theta$ UMVUE不一定存在,若存在,则它一定是充分统计量的函数;
- 若$\theta$ 某个无偏估计$\hat{\theta}$ 是充分统计量$T=T(x_1,…,x_n)$ 函数,则通过条件期望可以获得一个新的无偏估计$\widetilde{\theta}=E(\hat{\theta|T})$,且方差比原估计的方差要小;
- 考虑$\theta$ 估计时,只需要在其充分统计量的函数中寻找即可,该说法对所有统计推断都是正确的,这便是充分性原则。
区间估计
区间估计的概念
双侧区间
设$\theta$ 总体的一个参数,其参数空间为$\Theta$,$x_1,…,x_n$ 来自该总体的样本,对给定的一个$\alpha\quad(0<\alpha<1)$,假设有两个统计量$\hat{\theta}_L=\hat{\theta}_L(x_1,…,x_n)$ $\hat{\theta}_U=\hat{\theta}U(x_1,…,x_n)$,若对任意的$\theta\in\Theta$,有
$$
P\theta(\hat{\theta}_L\leq\theta\leq\hat{\theta}_U)\geq(=)1-\alpha
$$
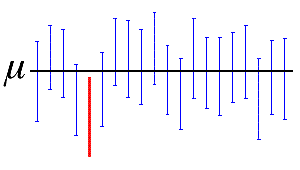
其中,总体为连续分布时取等号,表示用足了置信水平。称随机区间$[\hat{\theta}_L,\hat{\theta}_U]$ $\theta$ 置信水平为$1-\alpha$ 置信区间,或简称$[\hat{\theta}_L,\hat{\theta}_U]$ $\theta$ $1-\alpha$ 信区间,$\hat{\theta}_L$ $\hat{\theta}_U$ 别称为$\theta$ 置信下限和置信上限。置信水平$1-\alpha$ 频率解释:在大量的区间估计观测值中,至少有$100(1-\alpha)%$ 含$\theta$,如下图所示,其置信度为0.95.

单侧区间
设$\hat{\theta}_L=\hat{\theta}L(x_1,…,x_n)$ 统计量,对给定的$\alpha\in(0,1)$ 任意的$\theta\in\Theta$,有
$$
P\theta(\hat{\theta}_L\leq\theta)\geq1-\alpha,\quad\forall\theta\in\Theta
$$
则称$\hat{\theta}_L$ $\theta$ 置信水平为$1-\alpha$ 置信下限。同理,设$\hat{\theta}_U=\hat{\theta}U(x_1,…,x_n)$ 统计量,对给定的$\alpha\in(0,1)$ 任意的$\theta\in\Theta$,有
$$
P\theta(\hat{\theta}_L\geq\theta)\geq1-\alpha,\quad\forall\theta\in\Theta
$$
则称$\hat{\theta}_L$ $\theta$ 置信水平为$1-\alpha$ 置信上限。
区间估计的方法
枢轴量法
Step 1:设法构造一个样本和$\theta$ 函数$G=G(x_1,…,x_n,\theta)$ 得**$G$ 分布不依赖于未知参数**,称具有这种性质的$G$ 枢轴量。
Step 2:适当地选择两个常数c,d,使对给定的$\alpha\quad(0<\alpha<1)$,有
$$
P(c\leq G\leq d)=1-\alpha
$$
(在离散场合,将上式等号改为$\geq$)Step 3:假如能将$c\leq G\leq d$ 行不等式等价变形化为$\hat{\theta}_L\leq\theta\leq\hat{\theta}U$,则有
$$
P\theta(\hat{\theta}_L\leq\theta\leq\hat{\theta}_U)=1-\alpha
$$
表明$[\hat{\theta}_L,\hat{\theta}_U]$ $\theta$ $1-\alpha$ 等置信区间。注 :满足条件的c和d有很多,最终选择的目的是希望平均长度$E_\theta(\hat{\theta}_U)-\hat{\theta}L$ 可能短,但在一些场合中很难做到这一点,因此可以选择c和d,使得两个尾部概率各为$\alpha/2$,即
$$
P\theta(G<c)=P_\theta(G>d)=\alpha/2
$$
得到等尾置信区间。例:设$x_1,…,x_n$ 来自均匀总体$U(0,\theta)$ 一个样本,试对设定的$\alpha\ (0<\alpha<1)$ 出$\theta$ $1-\alpha$ 等置信区间。
解:三步法:
- 已知$\theta$ 最大似然估计为样本的最大次序统计量$x_{(n)}$,而$x_{(n)}/\theta$ 密度函数为
$$
p(y;\theta)=ny^{n-1},\quad 0<y<1
$$它与参数$\theta$ 关,故可取$x_{(n)}/\theta$ 为枢轴量$G$。
- 由于$x_{(n)}/\theta$ 分布函数为$F(y)=y^n$,$0<y<1$,故$P(c\leq x_{(n)}/\theta\leq d=d^n-c^n)$,因此可以选择适当的c和d满足
$$
d^n-c^n=1-\alpha
$$- 在$0\leq c<d\leq 1$ $d^n-c^n=1-\alpha$ 条件下,当$d=1, c=\sqrt[n]{\alpha}$ ,$E_\theta(\hat{\theta}U)-\hat{\theta}L$ 最小值,所以$[x{(n)},x{(n)}/\sqrt[n]{\alpha}]$ $1-\alpha$ 信区间
一些情况下的区间估计
单个正态总体参数的置信区间
- $\sigma$ 知时$\mu$ 置信区间:$[\bar{x}-u_{1-\alpha/2}\sigma/\sqrt{n},\quad\bar{x}+u_{1-\alpha/2}\sigma/\sqrt{n}]$
- $\sigma$ 知时$\mu$ 置信区间:$[\bar{x}-t_{1-\alpha/2}(n-1)s/\sqrt{n},\quad\bar{x}+t_{1-\alpha/2}(n-1)s/\sqrt{n}]$
- $\sigma^2$ 置信区间($\mu$ 知):$[(n-1)s^2/\chi^2_{1-\alpha/2}(n-1),\quad(n-1)s^2/\chi^2_{\alpha/2}(n-1)]$
大样本置信区间:$[\bar{x}-u_{1-\alpha/2}\sqrt{\frac{\bar{x}(1-\bar{x})}{n}},\quad \bar{x}+u_{1-\alpha/2}\sqrt{\frac{\bar{x}(1-\bar{x})}{n}}]$
两个正态总体下的置信区间
$\mu_1-\mu_2$ 置信区间
- $\sigma^2_1$ $\sigma^2_2$ 知时:$[\bar{x}-\bar{y}-u_{1-\alpha/2}\sqrt{\frac{\sigma^2_1}{m}+\frac{\sigma^2_2}{n}},\quad \bar{x}-\bar{y}+u_{1-\alpha/2}\sqrt{\frac{\sigma^2_1}{m}+\frac{\sigma^2_2}{n}}]$
- $\sigma^2_1=\sigma^2_2=\sigma^2$ 知时:$[\bar{x}-\bar{y}-\sqrt{\frac{m+n}{mn}}s_wt_{1-\alpha/2}(m+n-2),\quad \bar{x}-\bar{y}+\sqrt{\frac{m+n}{mn}}s_wt_{1-\alpha/2}(m+n-2)]$
- $\sigma^2_2/\sigma^2_1=c$ 知时:$[\bar{x}-\bar{y}-\sqrt{\frac{mc+n}{mn}}s_wt_{1-\alpha/2}(m+n-2),\quad \bar{x}-\bar{y}+\sqrt{\frac{mc+n}{mn}}s_wt_{1-\alpha/2}(m+n-2)]$
- 当m和n都很大时的近似置信区间:$[\bar{x}-\bar{y}-u_{1-\alpha/2}\sqrt{\frac{s^2_x}{m}+\frac{s^2_y}{n}},\quad \bar{x}-\bar{y}+u_{1-\alpha/2}\sqrt{\frac{s^2_x}{m}+\frac{s^2_y}{n}}]$
- 一般情况下的近似置信区间:$[\bar{x}-\bar{y}-s_0t_{1-\alpha/2}(l),\quad \bar{x}-\bar{y}+s_0t_{1-\alpha/2}(l)]$
$\sigma^2_1/\sigma^2_2$ 置信区间:$[\frac{s_x^2}{s_y^2}\cdot\frac{1}{F_{1-\alpha/2(m-1,n-1)}},\quad \frac{s_x^2}{s_y^2}\cdot\frac{1}{F_{\alpha/2(m-1,n-1)}}]$
最大似然估计
Maximum Likelihood Estimation
最大似然估计原理:利用已知的样本,找出最有可能生成该样本的参数。
基本假设
- 参数$\theta$ 确定(非随机) 的而未知的量
- 按类别把样本集分开, $R_j$ 中的每个样本都是独立地从概率密度为$p(x|w_j)$ 总体中独立地抽取出来的 – 独立同分布
- 类条件概率密度$p(x|w_j)$ 已知分布, 参数向量未知
- 假设$R_j$ 不包含关于$\theta_j(j\neq i)$ 信息, 即不同类别的参数在函数上是独立的
似然函数
似然性(likelihood)与概率(possibility)同样可以表示事件发生的可能性大小,但是二者有着很大的区别:
- 概率$p(x\mid\theta)$ 是在已知参数$\theta$ 的情况下,发生观测结果$x$ 可能性大小;
- 似然性$L(\theta\mid x) $ 则是从观测结果$x$ 出发,分布函数的参数为$\theta$ 的可能性大小;
可能听着不是那么好理解。我们再详细说明下,似然函数如下:
$$
L(\theta\mid x)=p(x\mid\theta)
$$
其中$x$ 知,$\theta$ 未知。若对于两个参数 $\theta_1$ $\theta_2$ ,有
$$
L(\theta_1\mid x)=p(x\mid\theta_1) > p(x\mid\theta_2)=L(\theta_2\mid x)
$$
那么意味着 时,随机变量 生成 的概率大于当参数 时。这也正是似然的意义所在,若观测数据为 ,那么 是比 更有可能为分布函数的参数。
在不同的时候, 可以表示概率也可以用于计算似然,这里给出个人的理解,整理如下:
- 在 已知, 为变量的情况下, 为概率,表示通过已知的分布函数与参数,随机生成出 的概率;
- 在 为变量, 已知的情况下, 为似然函数,它表示对于不同的 ,出现 的概率是多少。此时可写成 $L(\theta\mid x)=p(x\mid\theta)$,更严格地,我们也可写成 。
最大似然估计
搞清楚了似然函数,就可以进阶到最大似然估计了。
最大似然估计的思想在于,对于给定的观测数据 $x$,我们希望能从所有的参数 $\theta_1, \theta_2, \cdots, \theta_n $ 中找出能最大概率生成观测数据的参数 作为估计结果。
回到前面所说的似然函数,被估计出的参数 应该满足:
那么在实际运算中,我们将待估计的参数 看成是变量,计算得到生成观测数据 的概率函数 ,并找到能最大化概率函数的参数即可:
而这最大化的步骤通过求导等于0来解得。
给出维基百科的例子来加深理解:

离散型随机变量的最大似然估计
离散型随机变量 的分布律为 ,设 为来自 的样本, 为相应的观察值, 为待估参数。
在参数 下,分布函数随机取到 的概率为
构造似然函数:

可知似然函数是一个关于 的函数,要找到最大概率生成 的参数,即找到当 取最大值时的 。
求解出最大值,通常的方法就是求导=0:
由于式子通常是累乘的形式,我们借助对数函数来简化问题:
上式也通常被称作对数似然方程。如果 包含多个参数 $\theta_1, \theta_2, \cdots, \theta_k$,可对多个参数分别求偏导来连立方程组。下面举一个例子:

连续型随机变量的最大似然估计
连续型随机变量 的概率密度为 ,设 为来自 的样本,为相应的观察值,同样地, 为待估参数。
概率密度的图像与横轴所围成的面积大小代表了概率的大小,当随机变量$X$ 到了某一个值 $x_1$,可看做是选取到了 与 所围成的小矩形。如图所示:
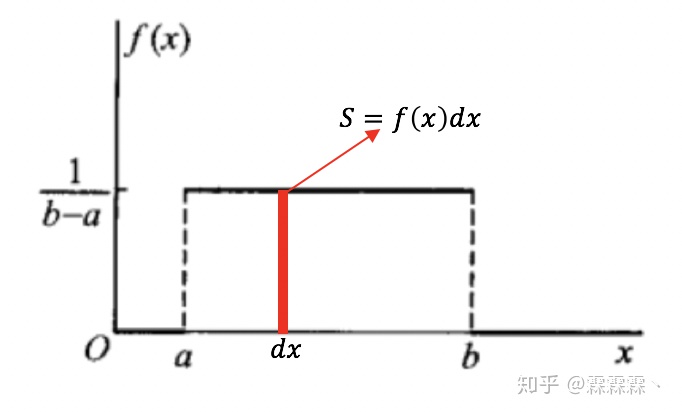
接着与离散型随机变量类似,随机取到观察值 的概率为:
构造似然函数:
由于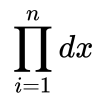 不随参数变化,故我们选择忽略,似然函数变为:
不随参数变化,故我们选择忽略,似然函数变为:
接着计算步骤和离散型类似,取对数求导等于0。例如:

Reference
- https://zhuanlan.zhihu.com/p/55791843
- 《概率论与数理统计》第四版
- 维基百科-似然性
- 最大似然估计和最大后验估计(转) - 段子手实习生 - 博客园
- 详解最大似然估计(MLE)、最大后验概率估计(MAP),以及贝叶斯公式的理解 - nebulaf91的博客 - CSDN博客
- 如何理解似然函数?
贝叶斯估计
Bayesian Estimation
贝叶斯估计实质: 贝叶斯决策来决策参数的取值。与最大似然估计同为概率密度估计中的主要参数估计方法,结果多数情况下与最大似然估计相同
区别:
- 最大似然估计把待估计的参数当作未知但固定的量
- 贝叶斯估计把待估计的参数也看为随机变量
$R(\hat{\theta}|x )$ 给定$x$ 件下估计量$\hat{\theta}$ 期望损失,称为条件风险。 如果$\theta$ 估计量$\hat{\theta}$ 得条件风险最小,则称$\hat{\theta}$ ${\theta}$ 贝叶斯估计量



