
正则化
正则化
正则化主要用于避免过拟合的产生和减少网络误差。
正则化一般具有如下形式:
$$
J(w,b)= \frac{1}{m} \sum_{i=1}^{m}L(f(x),y)+\lambda R(f)
$$
其中,第 1 项是经验风险,第 2 项是正则项, $λ≥0$ 为调整两者之间关系的系数。
第 1 项的经验风险较小的模型可能较复杂(有多个非零参数),这时第 2 项的模型复杂度会较大。
正则化的作用是选择经验风险与模型复杂度同时较小的模型。
常见的有正则项有 L1 正则 和 L2 正则 以及 Dropout ,其中 L2 正则 的控制过拟合的效果比 L1 正则 的好。
拟合问题
对于拟合的表现,可以分为三类情况:
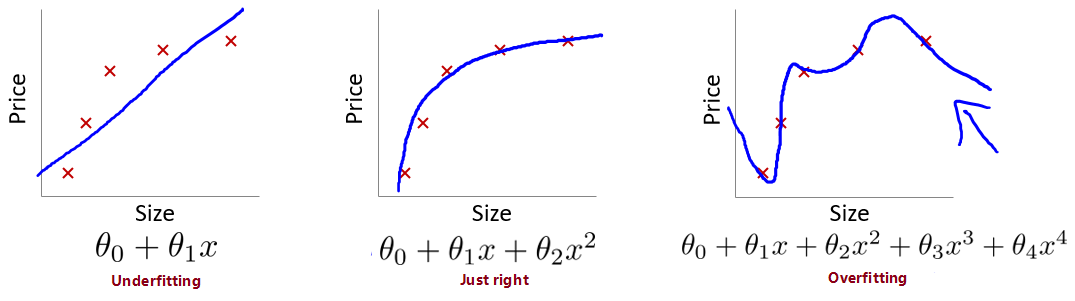
欠拟合(Underfitting)
无法很好的拟合训练集中的数据,预测值和实际值的误差很大,这类情况被称为欠拟合。拟合模型比较简单(特征选少了)时易出现这类情况。类似于,你上课不好好听,啥都不会,下课也差不多啥都不会。
优良的拟合(Just right)
不论是训练集数据还是不在训练集中的预测数据,都能给出较为正确的结果。类似于,学霸学神!
过拟合(Overfitting)
能很好甚至完美拟合训练集中的数据,即 $J(\theta) \to 0$,但是对于不在训练集中的新数据,预测值和实际值的误差会很大,泛化能力弱,这类情况被称为过拟合。拟合模型过于复杂(特征选多了)时易出现这类情况。类似于,你上课跟着老师做题都会都听懂了,下课遇到新题就懵了不会拓展。
线性模型中的拟合情况(左图欠拟合,右图过拟合):
逻辑分类模型中的拟合情况:

为了度量拟合表现,引入:
偏差(bias)
指模型的预测值与真实值的偏离程度。偏差越大,预测值偏离真实值越厉害。偏差低意味着能较好地反应训练集中的数据情况。
方差(Variance)
指模型预测值的离散程度或者变化范围。方差越大,数据的分布越分散,函数波动越大,泛化能力越差。方差低意味着拟合曲线的稳定性高,波动小。
据此,我们有对同一数据的各类拟合情况如下图:

据上图,高偏差意味着欠拟合,高方差意味着过拟合。
我们应尽量使得拟合模型处于低方差(较好地拟合数据)状态且同时处于低偏差(较好地预测新值)的状态。
避免过拟合的方法有:
- 减少特征的数量
- 手动选取需保留的特征
- 使用模型选择算法来选取合适的特征(如 PCA 算法)
- 减少特征的方式易丢失有用的特征信息
- 正则化(Regularization)
- 可保留所有参数(许多有用的特征都能轻微影响结果)
- 减少/惩罚各参数大小(magnitude),以减轻各参数对模型的影响程度
- 当有很多参数对于模型只有轻微影响时,正则化方法的表现很好
代价函数
很多时候由于特征数量过多,过拟合时我们很难选出要保留的特征,这时候应用正则化方法则是很好的选择。
上文中,$\theta_0 + \theta_1x + \theta_2x^2 + \theta_3x^3 + \theta_4x^4$ 这样一个复杂的多项式较易过拟合,在不减少特征的情况下,如果能消除类似于 $\theta_3x^3$、$\theta_4x^4$ 等复杂部分,那复杂函数就变得简单了。
为了保留各个参数的信息,不修改假设函数,改而修改代价函数:
$$
min_\theta\ \dfrac{1}{2m}\sum_{i=1}^m (h_\theta(x^{(i)}) - y^{(i)})^2 + 1000\cdot\theta_3^2 + 1000\cdot\theta_4^2
$$
上式中,我们在代价函数中增加了 $\theta_3$、$\theta_4$ 的惩罚项(penalty term) $1000\cdot\theta_3^2 + 1000\cdot\theta_4^2$,如果要最小化代价函数,那么势必需要极大地减小 $\theta_3$、$\theta_4$,从而使得假设函数中的 $\theta_3x^3$、$\theta_4x^4$ 这两项的参数非常小,就相当于没有了,假设函数也就**“变得”简单**了,从而在保留各参数的情况下避免了过拟合问题。

根据上面的讨论,有时也无法决定要减少哪个参数,故统一惩罚除了 $\theta_0$ 外的所有参数。
代价函数:
$$
J\left( \theta \right)=\frac{1}{2m}[\sum\limits_{i=1}^{m}{{{({h_\theta}({{x}^{(i)}})-{{y}^{(i)}})}^{2}}+\lambda \sum\limits_{j=1}^{n}{\theta_{j}^{2}}]}
$$
$\lambda$: 正则化参数(Regularization Parameter),$\lambda > 0$
$\sum\limits_{j=1}^{n}$: 不惩罚基础参数 $\theta_0$
$\lambda \sum\limits_{j=1}^{n}{\theta_{j}^{2}}$: 正则化项
$\lambda$ 正则化参数类似于学习速率,也需要我们自行对其选择一个合适的值。
- 过大
- 导致模型欠拟合(假设可能会变成近乎 $x = \theta_0$ 的直线 )
- 无法正常去过拟问题
- 梯度下降可能无法收敛
- 过小
- 无法避免过拟合(等于没有)
正则化符合奥卡姆剃刀(Occam’s razor)原理。在所有可能选择的模型中,能够很好地解释已知数据并且十分简单才是最好的模型,也就是应该选择的模型。从贝叶斯估计的角度来看,正则化项对应于模型的先验概率。可以假设复杂的模型有较大的先验概率,简单的模型有较小的先验概率。
正则化是结构风险最小化策略的实现,是去过拟合问题的典型方法,虽然看起来多了个一参数多了一重麻烦,后文会介绍自动选取正则化参数的方法。模型越复杂,正则化参数值就越大。比如,正则化项可以是模型参数向量的范数。
正则化的线性回归
应用正则化的线性回归梯度下降算法:
$$
\begin{align*}
& \text{Repeat}\ \lbrace \
& \ \ \ \ \theta_0 := \theta_0 - \alpha\ \frac{1}{m}\ \sum_{i=1}^m (h_\theta(x^{(i)}) - y^{(i)})x_0^{(i)} \
& \ \ \ \ \theta_j := \theta_j - \alpha\ \left[ \left( \frac{1}{m}\ \sum_{i=1}^m (h_\theta(x^{(i)}) - y^{(i)})x_j^{(i)} \right) + \frac{\lambda}{m}\theta_j \right], \ \ \ j \in \lbrace 1,2…n\rbrace\
& \rbrace
\end{align*}
$$
也可以移项得到更新表达式的另一种表示形式
$$
\theta_j := \theta_j(1 - \alpha\frac{\lambda}{m}) - \alpha\frac{1}{m}\sum_{i=1}^m(h_\theta(x^{(i)}) - y^{(i)})x_j^{(i)}
$$
$\frac{\lambda}{m}\theta_j$: 正则化项
应用正则化的正规方程法:
$$
\begin{align*}
& \theta = \left( X^TX + \lambda \cdot L \right)^{-1} X^Ty \
& \text{where}\ \ L = \begin{bmatrix} 0 & & & & \
& 1 & & & \
& & 1 & & \
& & & \ddots & \
& & & & 1 \ \end{bmatrix}
\end{align*}
$$
$\lambda\cdot L$: 正则化项
$L$: 第一行第一列为 $0$ 的 $n+1$ 维单位矩阵
前文提到正则化可以解决正规方程法中不可逆的问题,即增加了 $\lambda \cdot L$ 正则化项后,可以保证 $X^TX + \lambda \cdot L$ 可逆(invertible),即便 $X^TX$ 不可逆(non-invertible)。
正则化的逻辑回归
为逻辑回归的代价函数添加正则化项:
$$
J(\theta) = - \frac{1}{m} \sum_{i=1}^m \large[ y^{(i)}\ \log (h_\theta (x^{(i)})) + (1 - y^{(i)})\ \log (1 - h_\theta(x^{(i)}))\large] + \frac{\lambda}{2m}\sum_{j=1}^n \theta_j^2
$$
前文已经证明过逻辑回归和线性回归的代价函数的求导结果是一样的,此处通过给正则化项添加常数 $\frac{1}{2}$,则其求导结果也就一样了。
从而有应用正则化的逻辑回归梯度下降算法:
$$
\begin{align*}
& \text{Repeat}\ \lbrace \
& \ \ \ \ \theta_0 := \theta_0 - \alpha\ \frac{1}{m}\ \sum_{i=1}^m (h_\theta(x^{(i)}) - y^{(i)})x_0^{(i)} \
& \ \ \ \ \theta_j := \theta_j - \alpha\ \left[ \left( \frac{1}{m}\ \sum_{i=1}^m (h_\theta(x^{(i)}) - y^{(i)})x_j^{(i)} \right) + \frac{\lambda}{m}\theta_j \right], \ \ \ j \in \lbrace 1,2…n\rbrace\
& \rbrace \end{align*}
$$
我们用逻辑回归来实现这些设想,求成本函数$J$ 最小值,它是我们定义的成本函数,参数包含一些训练数据和不同数据中个体预测的损失,$w$ $b$ 逻辑回归的两个参数,$w$ 一个多维度参数矢量,$b$ 一个实数。在逻辑回归函数中加入正则化,只需添加参数 $\lambda$,也就是正则化参数。
正则化方法
Lp范数
$L_{p}$ 正则的 $L$ 是指 $L_{p}$ 范数,其定义为:
$L_{0}$ 范数: $\left | w \right |{0} = #(i)\ with \ x{i} \neq 0$ (非零元素的个数)
$L_{1}$ 范数: $\left | w \right |{1} = \sum{i = 1}^{d}\lvert x_i\rvert$ (每个元素绝对值之和)
$L_{2}$ 范数: $\left | w \right |{2} = \Bigl(\sum{i = 1}^{d} x_i^2\Bigr)^{1/2}$ (欧氏距离)
$L_{p}$ 范数: $\left | w \right |{p} = \Bigl(\sum{i = 1}^{d} x_i^p\Bigr)^{1/p}$
在机器学习中,若使用了 $\lVert w\rVert_p$ 作为正则项,我们则说该机器学习任务引入了 $L_{p}$ 正则项。

上图来自周志华老师的《机器学习》插图
L1 正则
$$
J(w,b)=\frac{1}{m} \sum_{i=1}^{m}L(\hat{y},y)+\frac{\lambda }{m}\left | w \right |_{1}
$$
- 凸函数,不是处处可微分
- 得到的是稀疏解(最优解常出现在顶点上,且顶点上的 $w$ 只有很少的元素是非零的)
如果用的是$L1$ 则化,$w$ 最终会是稀疏的,也就是说$w$ 量中有很多 0,有人说这样有利于压缩模型,因为集合中参数均为 0,存储模型所占用的内存更少。实际上,虽然$L1$ 则化使模型变得稀疏,却没有降低太多存储内存,所以我认为这并不是$L1$ 正则化的目的,至少不是为了压缩模型,人们在训练网络时,越来越倾向于使用$L2$ 正则化。
L2 正则/ Weight Decay
$$
J(w,b)=\frac{1}{m} \sum_{i=1}^{m}L(\hat{y},y)+\frac{\lambda }{2m}\left | w \right |^{2}_{2}
$$
- 凸函数,处处可微分
- 易于优化
L2 regularization和Weight decay只在SGD优化的情况下是等价的。
1.weight decay
Weight decay是在每次更新的梯度基础上减去一个梯度( $\boldsymbol{\theta}$ 为模型参数向量, $\nabla f_{t}\left(\boldsymbol{\theta}{t}\right)$ 为 $t$ 时刻loss函数的梯度, $\alpha$ 为学习率):
$\boldsymbol{\theta}{t+1}=(1-\lambda) \boldsymbol{\theta}{t}-\alpha \nabla f{t}\left(\boldsymbol{\theta}{t}\right)\$
2.L2 regularization
L2 regularization是给参数加上一个L2惩罚( $f{t}(\boldsymbol{\theta})$ 为loss函数):
$f_{t}^{r e g}(\boldsymbol{\theta})=f_{t}(\boldsymbol{\theta})+\frac{\lambda^{\prime}}{2}|\boldsymbol{\theta}|_{2}^{2}\$
(当 $\lambda^{\prime}=\frac{\lambda}{\alpha}$ 时,与weight decay等价,仅在使用标准SGD优化时成立)
Dropout
Dropout 主要用于神经网络,其原理是使神经网络中的某些神经元随机失活,让模型不过度依赖某一神经元,达到增强模型鲁棒性以及控制过拟合的效果。
除了$L2$ 则化,还有一个非常实用的正则化方法——“Dropout(随机失活)”,我们来看看它的工作原理。

假设你在训练上图这样的神经网络,它存在过拟合,这就是dropout所要处理的,我们复制这个神经网络,dropout会遍历网络的每一层,并设置消除神经网络中节点的概率。假设网络中的每一层,每个节点都以抛硬币的方式设置概率,每个节点得以保留和消除的概率都是 0.5,设置完节点概率,我们会消除一些节点,然后删除掉从该节点进出的连线,最后得到一个节点更少,规模更小的网络,然后用backprop方法进行训练。


这是网络节点精简后的一个样本,对于其它样本,我们照旧以抛硬币的方式设置概率,保留一类节点集合,删除其它类型的节点集合。对于每个训练样本,我们都将采用一个精简后神经网络来训练它,这种方法似乎有点怪,单纯遍历节点,编码也是随机的,可它真的有效。不过可想而知,我们针对每个训练样本训练规模小得多的网络,最后你可能会认识到为什么要正则化网络,因为我们在训练规模小得多的网络。
其他方法
- 数据扩增
- early stopping
QA
为什么只正则化参数$w$?为什么不再加上参数 $b$ 呢?
你可以这么做,只是我习惯省略不写,因为$w$ 常是一个高维参数矢量,已经可以表达高偏差问题,$w$ 能包含有很多参数,我们不可能拟合所有参数,而 $b$ 是单个数字,所以 $w$ 乎涵盖所有参数,而不是$b$,如果加了参数$b$,其实也没太大影响,因为$b$ 是众多参数中的一个,所以我通常省略不计,如果你想加上这个参数,完全没问题。
为什么正则化有利于预防过拟合?
为什么正则化有利于预防过拟合呢?为什么它可以减少方差问题?我们通过两个例子来直观体会一下。

左图是高偏差,右图是高方差,中间是Just Right。
直观上理解就是如果正则化$\lambda$ 设置得足够大,权重矩阵$W$ 设置为接近于 0 的值,直观理解就是把多隐藏单元的权重设为 0,于是基本上消除了这些隐藏单元的许多影响。如果是这种情况,这个被大大简化了的神经网络会变成一个很小的网络,小到如同一个逻辑回归单元,可是深度却很大,它会使这个网络从过度拟合的状态更接近左图的高偏差状态。$\lambda$ 存在一个中间值,会有一个接近“Just Right”的中间状态。
直观理解就是$\lambda$ 加到足够大,$W$ 接近于 0,实际上是不会发生这种情况的,我们尝试消除或至少减少许多隐藏单元的影响,最终这个网络会变得更简单,这个神经网络越来越接近逻辑回归,我们直觉上认为大量隐藏单元被完全消除了,其实不然,实际上是该神经网络的所有隐藏单元依然存在,但是它们的影响变得更小了。神经网络变得更简单了,貌似这样更不容易发生过拟合,因此我不确定这个直觉经验是否有用,不过在编程中执行正则化时,你实际看到一些方差减少的结果。



Reference
[1] LeCun, Y., Bottou, L., Orr, G., and Muller, K. Efficient backprop. In Orr, G. and K., Muller (eds.), Neural Net-works: Tricks of the trade. Springer, 1998b.
[2] Sergey Ioffe, Christian Szegedy, “Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift”, arXiv preprint arXiv:1502.03167, 2015.
[3] 李航. 统计方法学 P13-14
[4] 聊聊机器学习中的损失函数 [http://kubicode.me/2016/04/11/Machine Learning/Say-About-Loss-Function/](http://kubicode.me/2016/04/11/Machine Learning/Say-About-Loss-Function/)
[5] Nitish Srivastava, Geoffrey Hinton, Alex Krizhevsky, Ilya Sutskever and Ruslan Salakhutdinov, “Dropout: A Simple Way to Prevent Neural Networks from
Overfitting”,



