
PCA
1.相关背景
在许多领域的研究与应用中,通常需要对含有多个变量的数据进行观测,收集大量数据后进行分析寻找规律。多变量大数据集无疑会为研究和应用提供丰富的信息,但是也在一定程度上增加了数据采集的工作量。更重要的是在很多情形下,许多变量之间可能存在相关性,从而增加了问题分析的复杂性。如果分别对每个指标进行分析,分析往往是孤立的,不能完全利用数据中的信息,因此盲目减少指标会损失很多有用的信息,从而产生错误的结论。
因此需要找到一种合理的方法,在减少需要分析的指标同时,尽量减少原指标包含信息的损失,以达到对所收集数据进行全面分析的目的。由于各变量之间存在一定的相关关系,因此可以考虑将关系紧密的变量变成尽可能少的新变量,使这些新变量是两两不相关的,那么就可以用较少的综合指标分别代表存在于各个变量中的各类信息。主成分分析与因子分析就属于这类降维算法。
2. 性质
缓解维度灾难:PCA 算法通过舍去一部分信息之后能使得样本的采样密度增大(因为维数降低了),这是缓解维度灾难的重要手段;
降维具有如下一些优点:
- 使得数据集更易使用。
- 降低算法的计算开销。
- 去除噪声。
- 使得结果容易理解。
降维的算法有很多,比如奇异值分解(SVD)、主成分分析(PCA)、因子分析(FA)、独立成分分析(ICA)。
降噪:当数据受到噪声影响时,最小特征值对应的特征向量往往与噪声有关,将它们舍弃能在一定程度上起到降噪的效果;
过拟合:PCA 保留了主要信息,但这个主要信息只是针对训练集的,而且这个主要信息未必是重要信息。有可能舍弃了一些看似无用的信息,但是这些看似无用的信息恰好是重要信息,只是在训练集上没有很大的表现,所以 PCA 也可能加剧了过拟合;
特征独立:PCA 不仅将数据压缩到低维,它也使得降维之后的数据各特征相互独立;
3.PCA原理详解
3.1 PCA的概念
PCA(Principal Component Analysis),即主成分分析方法,是一种使用最广泛的数据降维算法。PCA的主要思想是将n维特征映射到k维上,这k维是全新的正交特征也被称为主成分,是在原有n维特征的基础上重新构造出来的k维特征。PCA的工作就是从原始的空间中顺序地找一组相互正交的坐标轴,新的坐标轴的选择与数据本身是密切相关的。其中,第一个新坐标轴选择是原始数据中方差最大的方向,第二个新坐标轴选取是与第一个坐标轴正交的平面中使得方差最大的,第三个轴是与第1,2个轴正交的平面中方差最大的。依次类推,可以得到n个这样的坐标轴。通过这种方式获得的新的坐标轴,我们发现,大部分方差都包含在前面k个坐标轴中,后面的坐标轴所含的方差几乎为0。于是,我们可以忽略余下的坐标轴,只保留前面k个含有绝大部分方差的坐标轴。事实上,这相当于只保留包含绝大部分方差的维度特征,而忽略包含方差几乎为0的特征维度,实现对数据特征的降维处理。
思考:我们如何得到这些包含最大差异性的主成分方向呢?
答案:事实上,通过计算数据矩阵的协方差矩阵,然后得到协方差矩阵的特征值特征向量,选择特征值最大(即方差最大)的k个特征所对应的特征向量组成的矩阵。这样就可以将数据矩阵转换到新的空间当中,实现数据特征的降维。
由于得到协方差矩阵的特征值特征向量有两种方法**:特征值分解**协方差矩阵、奇异值分解协方差矩阵,所以PCA算法有两种实现方法:基于特征值分解协方差矩阵实现PCA算法、基于SVD分解协方差矩阵实现PCA算法。
3.2协方差和散度矩阵
样本均值:
$$
\frac{1}{n} \sum_{i=1}^{n}x_i
$$
样本方差:
$$
S^2=\frac{1}{n-1} \sum_{i=1}^{n}(x_i- \overline{x})^2
$$
样本X和Y的协方差:
$$
Cov(X,Y)=E[(X-E(X))(Y-E(Y))]=\frac{1}{n-1} \sum_{i=1}^{n}(x_i- \overline{x})(y_i- \overline{y})
$$
由上面的公式,我们可以得到以下结论:
(1) 方差的计算公式是针对一维特征,即针对同一特征不同样本的取值来进行计算得到;而协方差则必须要求至少满足二维特征;方差是协方差的特殊情况。
(2) 方差和协方差的除数是$n-1$,这是为了得到方差和协方差的无偏估计。
协方差为正时,说明$X$ $Y$ 正相关关系;协方差为负时,说明$X$ $Y$ 负相关关系;协方差为0时,说明$X$ $Y$ 相互独立。$Cov(X,X)$ 是$X$ 方差。当样本是$n$ 数据时,它们的协方差实际上是协方差矩阵(对称方阵)。例如,对于3维数据$(x,y,z)$,计算它的协方差就是:
$$
Cov(X,Y,Z)=
\begin{bmatrix}
Cov(x,x) & Cov(x,y) & Cov(x,z)\
Cov(y,x) & Cov(y,y) & Cov(y,z)\
Cov(z,x) & Cov(z,y) & Cov(z,z)
\end{bmatrix}
$$
散度矩阵
$$
S=\sum_{k=1}^{n}(x_k- m)(x_k-m)^T\
m=\frac{1}{n} \sum_{k=1}^{n}x_k
$$
对于数据$X$ 散度矩阵为$XX^T$ 实协方差矩阵和散度矩阵关系密切,散度矩阵就是协方差矩阵乘以(总数据量-1)。因此它们的特征值和特征向量是一样的。这里值得注意的是,散度矩阵是SVD奇异值分解的一步,因此PCA和SVD是有很大联系。
3.3 特征值分解矩阵原理
(1) 特征值与特征向量
如果一个向量$v$ 矩阵A的特征向量,则可以表示为:$Av=\lambda v$
其中,$\lambda$ 特征向量$v$ 应的特征值,一个矩阵的一组特征向量是一组正交向量。
(2) 特征值分解矩阵
对于矩阵A,有一组特征向量$v$,将这组向量进行正交化单位化,就能得到一组正交单位向量。特征值分解,就是将矩阵A分解为如下式:$A = Q^{-1}\sum Q$
其中,Q是矩阵A的特征向量组成的矩阵,$\sum$ 是一个对角阵,对角线上的元素就是特征值。
3.4 SVD分解矩阵原理
奇异值分解是一个能适用于任意矩阵的一种分解的方法,对于任意矩阵A总是存在一个奇异值分解:$A = U\sum V^T$
假设A是一个$mn$ 矩阵,那么得到的$U$ 一个$mn$ 方阵,$U$ 面的正交向量被称为左奇异向量。$\sum$ 一个的矩阵,$\sum$ 了对角线其它元素都为0,对角线上的元素称为奇异值。$V^T$ $V$ 转置矩阵,是一个$n*n$ 矩阵,它里面的正交向量被称为右奇异值向量。而且一般来讲,我们会将$\sum$ 的值按从大到小的顺序排列。
SVD分解矩阵A的步骤:
(1) 求$AA^T$ 特征值和特征向量,用单位化的特征向量构成$U$。
(2) 求$A^TA$ 特征值和特征向量,用单位化的特征向量构成$V$。
(3) 将$AA^T$ 者$A^TA$ 特征值求平方根,然后构成 $\sum$。
3.5 PCA算法两种实现方法
(1) 基于特征值分解协方差矩阵实现PCA算法
输入:数据集$X={x_1,x_2,x_3,x_4,…x_n}$ ,需要降到$k$ 。
去平均值(即去中心化),即每一位特征减去各自的平均值。
计算协方差矩阵$\frac{1}{n}XX^T$,注:这里除或不除样本数量$n$ $n-1$,其实对求出的特征向量没有影响。
用特征值分解方法求协方差矩阵$\frac{1}{n}XX^T$ 特征值与特征向量。
对特征值从大到小排序,选择其中最大的k个。然后将其对应的$k$ 特征向量分别作为行向量组成特征向量矩阵$P$。
将数据转换到$k$ 特征向量构建的新空间中,即$Y=PX$。
(2) 基于SVD分解协方差矩阵实现PCA算法
输入:数据集,需要降到k维。
输入:数据集$X={x_1,x_2,x_3,x_4,…x_n}$ ,需要降到$k$ 。
去平均值(即去中心化),即每一位特征减去各自的平均值。
计算协方差矩阵。
通过SVD计算协方差矩阵的特征值与特征向量。
对特征值从大到小排序,选择其中最大的$k$ 。然后将其对应的$k$ 特征向量分别作为列向量组成特征向量矩阵。
将数据转换到$k$ 特征向量构建的新空间中。
在PCA降维中,我们需要找到样本协方差矩阵的最大$k$ 特征向量,然后用这最大的$k$ 特征向量组成的矩阵来做低维投影降维。可以看出,在这个过程中需要先求出协方差矩阵,当样本数多、样本特征数也多的时候,这个计算还是很大的。当我们用到SVD分解协方差矩阵的时候,SVD有两个好处:
- 有一些SVD的实现算法可以先不求出协方差矩阵$XX^T$ 能求出我们的右奇异矩阵V。也就是说,我们的PCA算法可以不用做特征分解而是通过SVD来完成,这个方法在样本量很大的时候很有效。实际上,scikit-learn的PCA算法的背后真正的实现就是用的SVD,而不是特征值分解。
2)注意到PCA仅仅使用了我们SVD的左奇异矩阵,没有使用到右奇异值矩阵,那么右奇异值矩阵有什么用呢?
假设我们的样本是$mn$ 矩阵$X$,如果我们通过SVD找到了矩阵最大的$k$ 特征向量组成的$kn$ 矩阵 ,则我们可以做如下处理:$X_{mk}^{‘}=X_{mn}V_{n*k}^T$
可以得到一个$mk$ 矩阵$X$,这个矩阵和我们原来$mn$ 矩阵$X$ 比,列数从$n$ 到了$k$,可见对列数进行了压缩。也就是说,左奇异矩阵可以用于对行数的压缩;右奇异矩阵可以用于对列(即特征维度)的压缩。这就是我们用SVD分解协方差矩阵实现PCA可以得到两个方向的PCA降维(即行和列两个方向)。
4.理论推导
PCA有两种通俗易懂的解释:(1)最大方差理论;(2)最小化降维造成的损失。这两个思路都能推导出同样的结果。

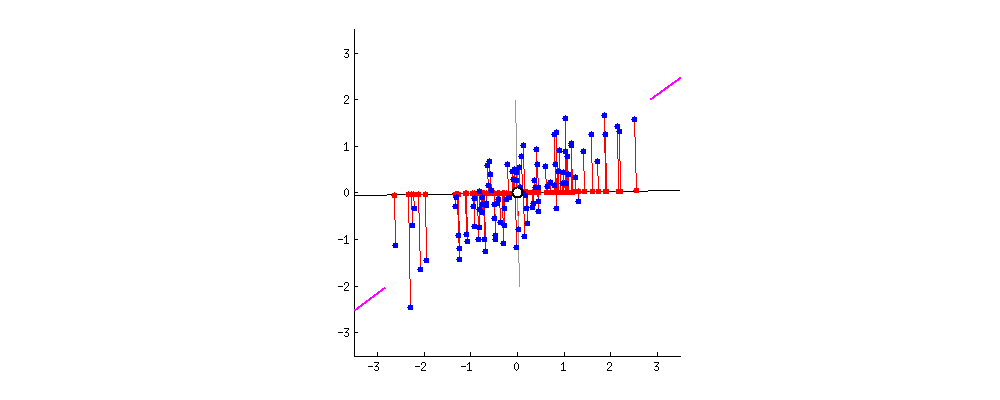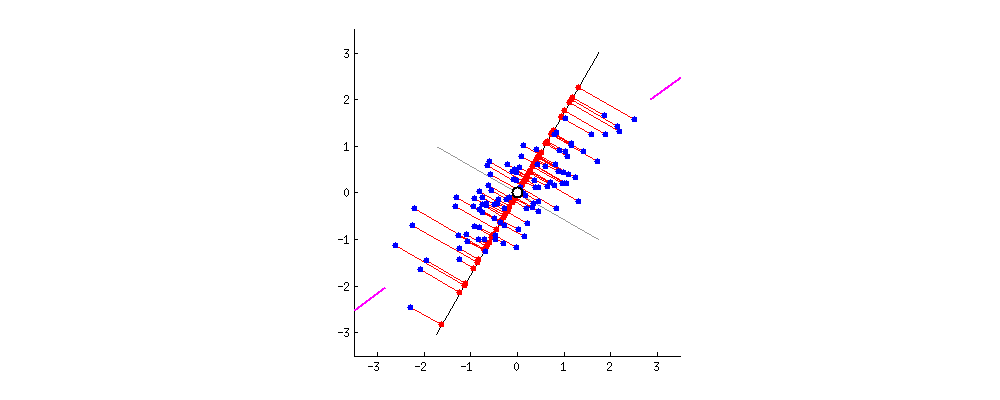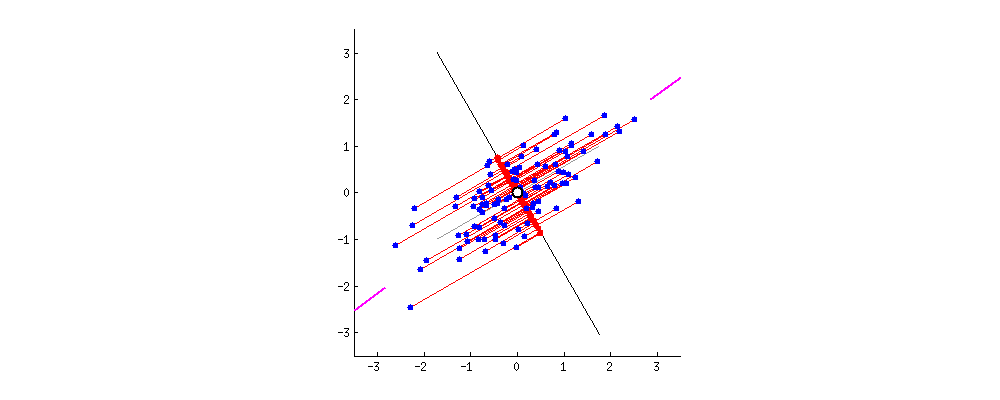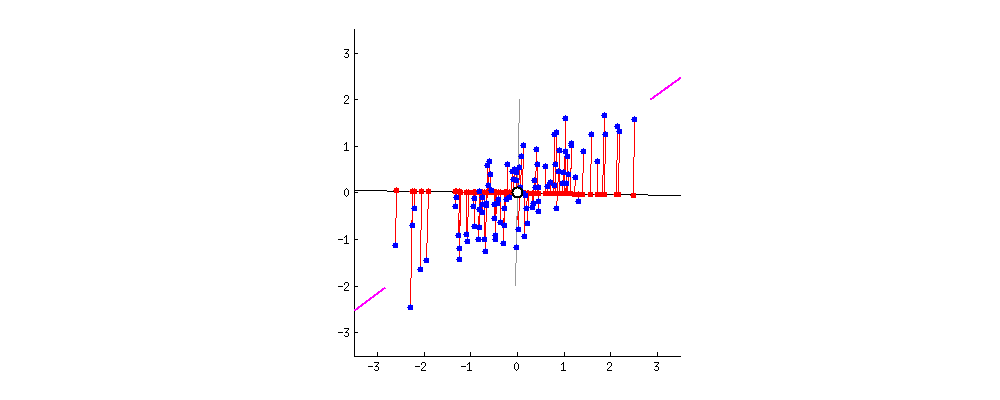
图中,红色点表示样例,蓝色点表示在$u$ 的投影,$u$ 直线的斜率也是直线的方向向量,而且是单位向量。蓝色点是在$u$ 的投影点,离原点的距离是$<x,u>$(即$X^TU$ 者$U^TX$)。
(1) 拉格朗日乘子法
在叙述求协方差矩阵对角化时,我们给出希望变化后的变量有**:变量间协方差为 0 且变量内方差尽可能大**。然后我们通过实对称矩阵的性质给予了推导,此外我们还可以把它转换为最优化问题利用拉格朗日乘子法来给予推导。
样本点$x_i$ 基$w$ 的坐标为:$(x_i,w) = x_{i}^Tw$,于是方差为:
$$
\begin{split}
D(x) &= \frac{1}{m}\sum_{i=1}^{m}(x_i^Tw)^2 \
&=\frac{1}{m}\sum_{i=1}^{m}(x_i^Tw)^T(x_i^Tw) \
&=\frac{1}{m}\sum_{i=1}^{m}w^Tx_ix_i^Tw \
&=w^T(\frac{1}{m}\sum_{i=1}^{m}x_ix_i^T)w
\end{split}
$$
其中$\frac{1}{m}\sum_{i=1}^{m}x_ix_i^T$ 原样本的协方差,令该矩阵为$\Lambda$,于是有
$$
D(x) = \begin{cases}
\max(w^T\Lambda w)\
s.t. w^Tw = 1
\end{cases}
$$
构造拉格朗日函数:$L(w) = w^T\Lambda w + \lambda (1-w^Tw)$,对$w$ 导,可得$\Lambda w = \lambda w$,此时
$$
D(x)=w^T\Lambda w= \lambda w^Tw = \lambda
$$
5. 细节
5.1 零均值化
当对训练集进行 PCA 降维时,也需要对验证集、测试集执行同样的降维。而对验证集、测试集执行零均值化操作时,均值必须从训练集计算而来,不能使用验证集或者测试集的中心向量。
其原因也很简单,因为我们的训练集时可观测到的数据,测试集不可观测所以不会知道其均值,而验证集再大部分情况下是在处理完数据后再从训练集中分离出来,一般不会单独处理。如果真的是单独处理了,不能独自求均值的原因是和测试集一样。
另外我们也需要保证一致性,我们拿训练集训练出来的模型用来预测测试集的前提假设就是两者是独立同分布的,如果不能保证一致性的话,会出现 Variance Shift 的问题。
5.2 与 SVD 的对比
这是两个不同的数学定义。我们先给结论**:特征值和特征向量是针对方阵才有的,而对任意形状的矩阵都可以做奇异值分解**。
PCA:方阵的特征值分解,对于一个方阵 A,总可以写成: $A=Q\Lambda Q^{-1}$。
其中,$Q$ 是这个矩阵$A$ 的特征向量组成的矩阵, $\Lambda$ 一个对角矩阵,每一个对角线元素就是一个特征值,里面的特征值是由大到小排列的,这些特征值所对应的特征向量就是描述这个矩阵变化方向(从主要的变化到次要的变化排列)。也就是说矩阵$A$ 的信息可以由其特征值和特征向量表示。
SVD:矩阵的奇异值分解其实就是对于矩阵$ A$ 的协方差矩阵$A^TA$ $AA^T$ 特征值分解推导出来的:
$$
A_{m,n}=U_{m,n}\Lambda_{m,n}V_{n,n}^T\approx U_{m,k} \Lambda {k,k}V{k,n}^T
$$
其中:$U V$ 都是正交矩阵,有$U^TU=I_m,V^TV=I_n$。这里的约等于是因为$\Lambda$ 有 $n$ 个奇异值,但是由于排在后面的很多接近 0,所以我们可以仅保留比较大的$k$ 奇异值。
$$
A^TA=(U\Lambda V^T)^T(U\Lambda V^T)=V\Lambda ^TU^TU\Lambda V^T=V\Lambda ^2V^T\
AA^T=(U\Lambda V^T)(U\Lambda V^T)^T=U\Lambda V^TV\Lambda^T U^T=U\Lambda ^2U^T
$$
所以,$V U$ 两个矩阵分别是$A^TA$ $AA^T$ 特征向量,中间的矩阵对角线的元素是 的特$A^TA$ $AA^T$ 值。我们也很容易看出 $A$ 的奇异值和 $A^TA$ 特征值之间的关系。
PCA 需要对协方差矩阵$C=\frac{1}{m}XX^T$ 行特征值分解; SVD 也是对$AA^T$ 行特征值分解。如果取$A=\frac{X^T}{\sqrt{m}}$ 两者基本等价。所以 PCA 问题可以转换成 SVD 求解。
而实际上 Sklearn 的 PCA 就是用 SVD 进行求解的,原因有以下几点:
- 当样本维度很高时,协方差矩阵计算太慢;
- 方阵特征值分解计算效率不高;
- SVD 除了特征值分解这种求解方式外,还有更高效更准确的迭代求解方式,避免了$A^TA$ 的计算;
- 其实 PCA 与 SVD 的右奇异向量的压缩效果相同。

参考文献:
主成分分析(PCA)原理详解_Microstrong-CSDN博客_pca
【机器学习】降维——PCA(非常详细) - 知乎 (zhihu.com)



