
梯度提升GB
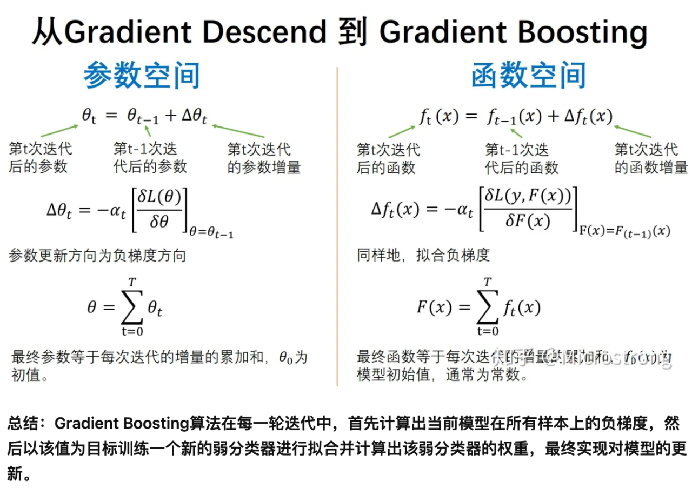
Gradient Boosting是Boosting中的一大类算法,它的思想借鉴于梯度下降法,其基本原理是根据当前模型损失函数的负梯度信息来训练新加入的弱分类器,然后将训练好的弱分类器以累加的形式结合到现有模型中。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Hongwei Zhao's Blog!
相关推荐

2025-11-16
PCA
1.相关背景在许多领域的研究与应用中,通常需要对含有多个变量的数据进行观测,收集大量数据后进行分析寻找规律。多变量大数据集无疑会为研究和应用提供丰富的信息,但是也在一定程度上增加了数据采集的工作量。更重要的是在很多情形下,许多变量之间可能存在相关性,从而增加了问题分析的复杂性。如果分别对每个指标进行分析,分析往往是孤立的,不能完全利用数据中的信息,因此盲目减少指标会损失很多有用的信息,从而产生错误的结论。 因此需要找到一种合理的方法,在减少需要分析的指标同时,尽量减少原指标包含信息的损失,以达到对所收集数据进行全面分析的目的。由于各变量之间存在一定的相关关系,因此可以考虑将关系紧密的变量...
2025-11-16
正交普鲁克问题
正交普鲁克问题 OrthogonalProcrustesProblem $$min||A\Omega - B||^2_F \s.t. \Omega^T\Omega=I$$其中,$A,B\in R^{m \times n}$已知,待求的$\Omega \in R^{n \times n}$ 正交矩阵。 $||X||F$ 为Frobenius范数,是矩阵范数的一种:$$||X||F= \sqrt{trace(X^TX)}=\sqrt{\sum{i,j}x{ij}^2}$$即所有元素的平方和。$$\begin{split}||A\Omega-B ||F^2&...

2025-11-16
KNN
KNN 简介假定我们现在有一个训练集,和一个测试集,对于其中一个测试样本,在训练集中找到与该样本最邻近的 $k$ 个样本,在这 $k$ 个样本中,如果多数样本属于某个类,就把测试样本分为这个类。 更为具体地说,KNN 的步骤是这样的: 根据给定的距离度量,在训练集 $T$ 中找出与测试样本 $x$ 最邻近的$k$ 点,涵盖这$k$ 点的 $x$ 的邻域记作 $N_k(x)$。 在 $N_k(x)$ 中根据分类决策规则(如多数表决)决定 $x$ 的类别 $y$。 KNN 的数学表达: $$\y=\arg \max {c j} \sum{x_{i} \in N_{k}(x)} ...
2025-11-16
K-means
K-means 是我们最常用的基于欧式距离的聚类算法,其认为两个目标的距离越近,相似度越大。 本文大致思路为:先介绍经典的牧师-村名模型来引入 K-means 算法,然后介绍算法步骤和时间复杂度,通过介绍其优缺点来引入算法的调优与改进,最后我们利用之前学的 EM 算法,对其进行收敛证明。 1. 算法1.1牧师-村民模型K-means 有一个著名的解释:牧师—村民模型: 有四个牧师去郊区布道,一开始牧师们随意选了几个布道点,并且把这几个布道点的情况公告给了郊区所有的村民,于是每个村民到离自己家最近的布道点去听课。听课之后,大家觉得距离太远了,于是每个牧师统计了一下自己的课上所有的村民的地...

2025-11-16
SVD
SVD性质 矩阵的奇异值分解一定存在,但不唯一; 奇异值唯一,但矩阵$U$ $V$ 不唯一; 矩阵$A$ $\sum$ 秩相等,等于正奇异值数量(包含重复的奇异值); SVD具体介绍特征值、特征向量、特征值分解特征值分解和奇异值分解(Singular Value Decomposition)在机器学习中都是很常见的矩阵分解算法。两者有着很紧密的关系,特征值分解和奇异值分解的目的都是一样,就是提取出一个矩阵最重要的特征。 特征值、特征向量如果一个向量$v$ 矩阵$A$ 特征向量,将一定可以表示成下面的形式:$Av=\lambda v$ 中,$\lambda$ 特征向量$v$ ...
2025-11-16
指数移动平均EDA
在深度学习中,经常会使用EMA(指数移动平均)这个方法对模型的参数做平均,以求提高测试指标并增加模型鲁棒。 EMA的定义指数移动平均(Exponential Moving Average)也叫权重移动平均(Weighted Moving Average),是一种给予近期数据更高权重的平均方法。 假设我们有$n$ 数据: $[\theta_1, \theta_2, …, \theta_n]$ 普通的平均数: $\overline{v}=\frac{1}{n}\sum_{i=1}^n \theta_i$ EMA: $v_t = \beta\cdot v_{t-...
