
AdaLoRA
一、AdaLoRA在做一件什么事
1.1 LoRA是怎么做微调的
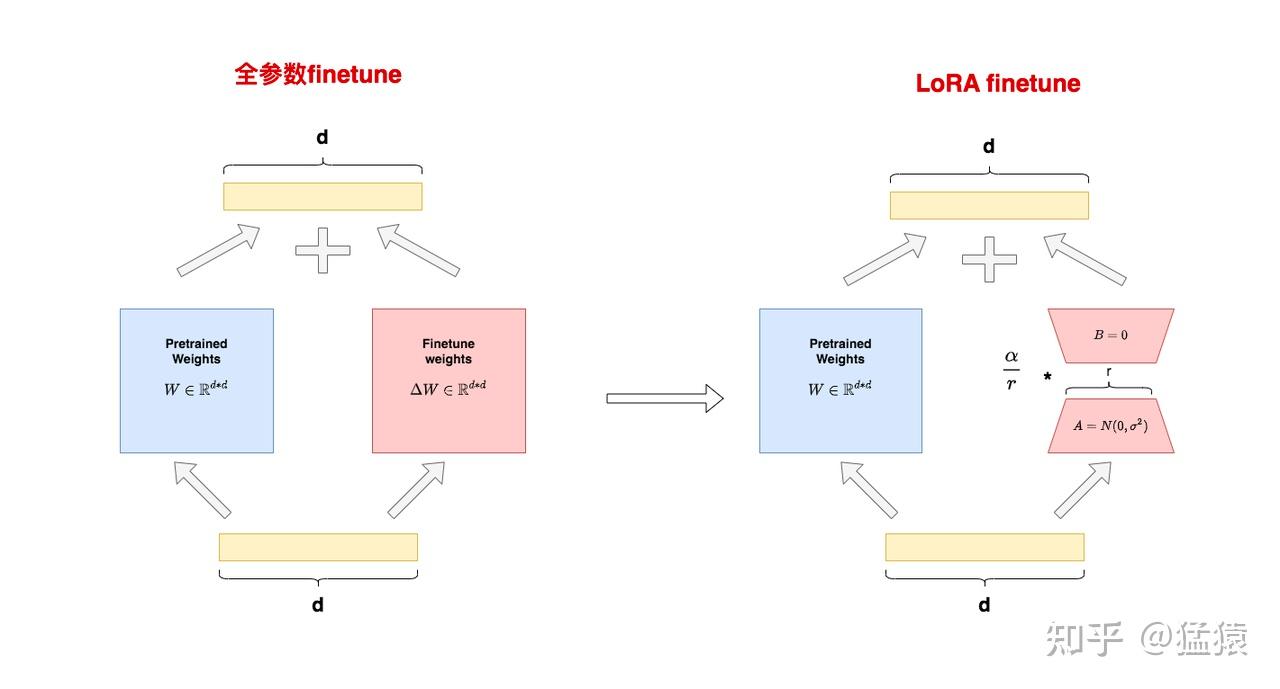
假设原始参数为 $W$ ,全参数微调后对原始参数的改变量为 $\Delta W$ 。在LoRA中,我们用两个矩阵的乘积 $BA$ 来近似$\Delta W$做SVD分解后的结果,则模型的输出结果满足:
$$
h = Wx + \Delta W x=Wx + \frac{\alpha}{r}BAx
$$
其中,$r$ 就是我们设定的矩阵的秩**,在微调过程中,所有做LoRA适配器的module,它们的 $r$ 都是一致的,且在训练过程中不会改变**(对秩的含义不理解的,可参见这篇文章的4.1。对 $\frac{\alpha}{r}$ 不了解的,可参见这篇文章的3.2)。在LoRA原始论文中,作者最终选择对attention模块的 $W_{q}, W_{v}$ 做低秩适配。
好,那么现在,问题来了:
- 对所有模块都采用同一个秩 $r$,这是合理的吗?
- 在微调过程中,一直保持秩 $r$ 不变,这是合理的吗?
我们来分别细看这两个问题。
1.2 对所有模块都采用同一个秩,是否合理
这个问题,早在AdaLoRA之前,LoRA的作者就意识到了,并做了如下实验:
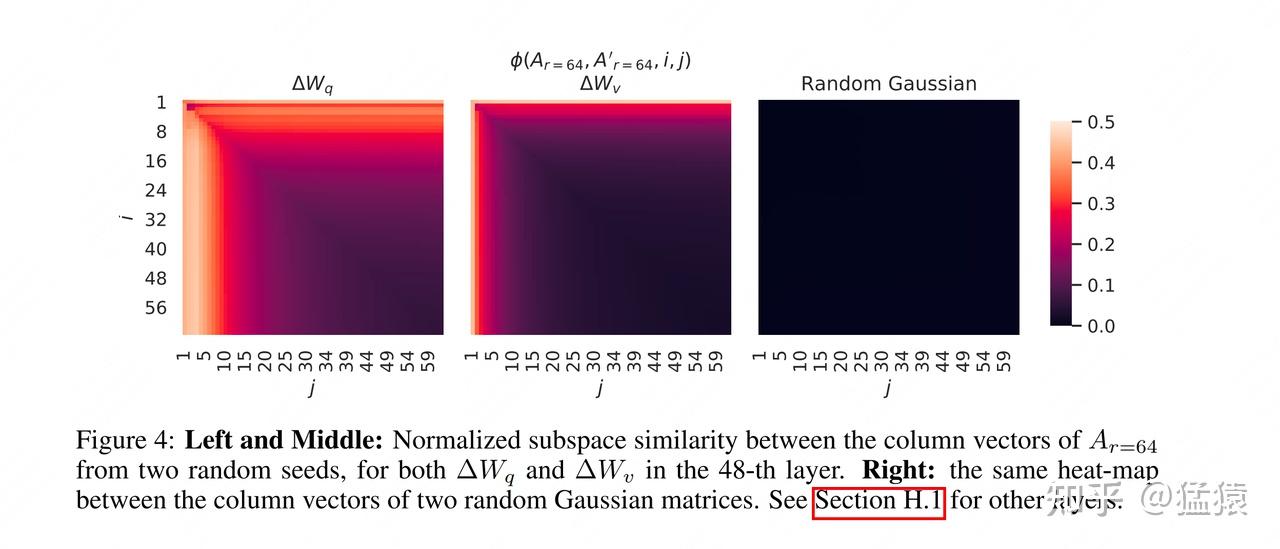
图中亮色表示对应模块的intrinsic rank(本征/内在秩),从中可以发现, $W_{q}$ 的intrinsic rank要大于 $W_{v}$ ,因此LoRA的作者在这里就挖了个可以让后人来填的坑:不同的模块可以用不同的秩。(对LoRA实验结果有疑惑的,可以看这篇文章第五部分)。
所以到了AdaLoRA这里,它的作者也做了两个实验:
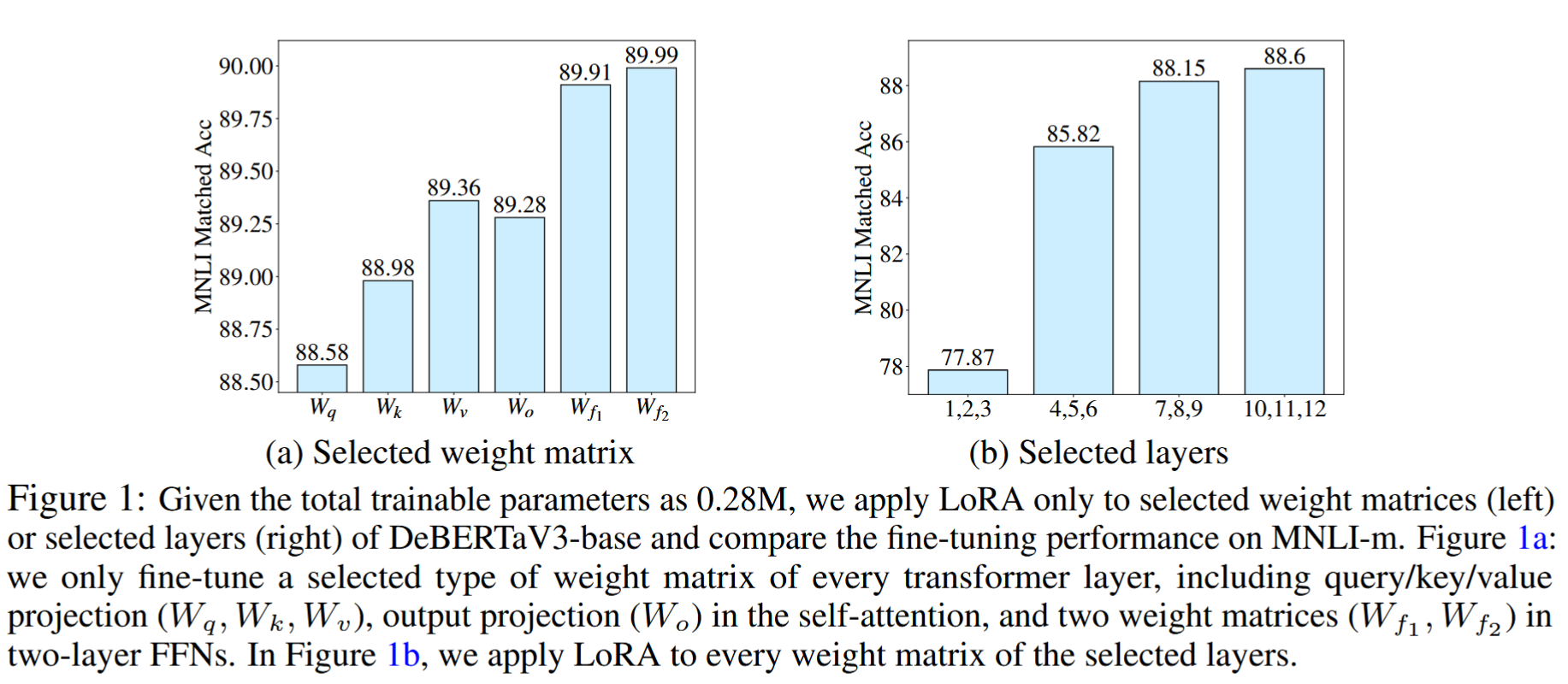
实验(a)对应着左图,作者使用LoRA,在模型的每个layer中微调特定的某个模块,然后去评估模型的效果。可以直观发现,微调不同模块时效果差异显著。
实验(b)对应着右图,作者使用LoRA,对模型不同layer的所有模块做微调。例如1,2,3表示对模型前三层的所有模块做lora微调。可以发现,微调不同layer时模型效果差异显著,微调最后三层的效果最好。
这些实验都证明了一件事:在使用LoRA微调时,对模型的不同模块使用相同的秩,显然是不合理的。
1.3 微调过程中一直保持秩不变,是否合理
对于这点,作者并没有做实验来说明,但我们可以从1.2的分析中得到一些思路。
在1.2中,我们通过实验证明“对不同模块采用不同秩”的必要性,那么接下来势必就要解决“每个模块的秩到底要设成多少”的问题。解答这个问题最直接的办法,就是交给模型去学。那模型学习的过程,肯定是个探索性的过程呀,理想情况下,你给模型一个初始化的秩,然后让它在训练过程中,学会慢慢调整这个秩,直到最优。所以,在微调step的更新过程中,秩也不会保持不变。
1.4 AdaLoRA的总体改进目标
好,到此为止,AdaLoRA的总体改进目标就出来了:
找到一种办法,让模型在微调过程中,去学习每个模块参数对训练结果(以loss衡量)的重要性。然后,根据重要性,动态地调整不同模块的秩。
作者管这样的策略叫**[参数预算](parameter budget)**,作为一个学财会出身的人,这真是非常形象了。待训练的参数越多,训练代价越大,因此做好参数预算方案,集中训练最重要的那些参数,ROI才会越高。
二、AdaLoRA的原理
2.1 SVD分解
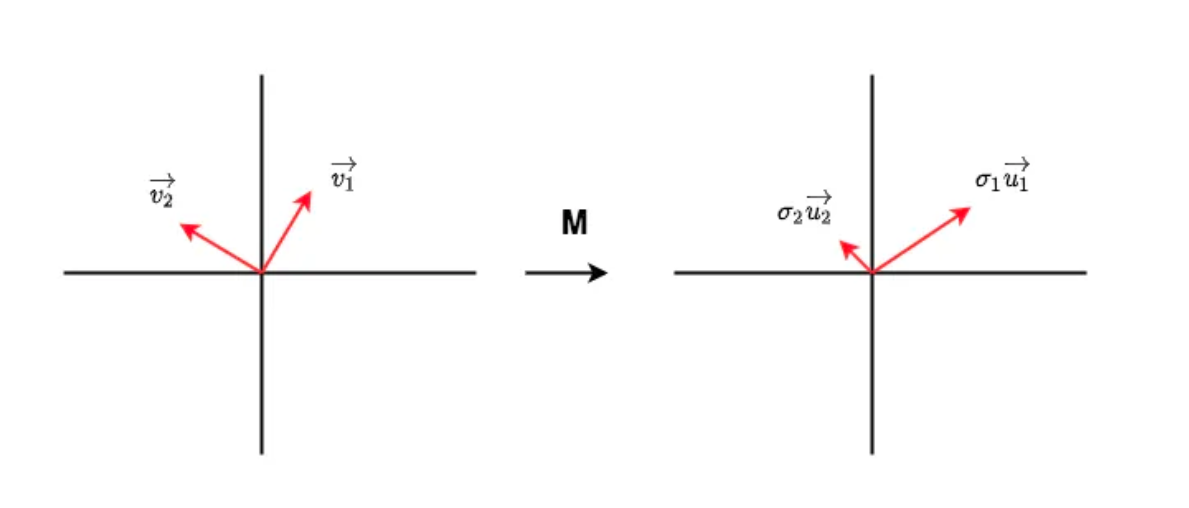
如图,矩阵 $M$ 是我们需要做信息量检查的矩阵。假设在输入数据的特征空间中,存在一组正交的单位向量 $\vec{v_1}, \vec{v_2}$ ,经过 $M$ 的变换后,它们变成另一组正交向量 $\sigma_1 \vec{u_1}, \sigma_2 \vec{u_2}$ ,其中 $\vec{u_1}, \vec{u_2}$ 也是一组正交的单位向量, $\sigma_1, \sigma_2$ 分别表示对应方向上的模。上面这一顿变幻,可以写成:
$$
M[\vec{v_1}, \vec{v_2}] = [\sigma_1 \vec{u_1}, \sigma_2 \vec{u_2}]
$$
稍加改写,就有:
$$
M = \begin{bmatrix}\vec{u_1}&\vec{u_2}\end{bmatrix}\begin{bmatrix}\sigma_1&0 \0&\sigma_2\end{bmatrix}\begin{bmatrix}\vec{v_1}\\vec{v_2}\end{bmatrix}
$$
不难发现, $\sigma_{1}, \sigma_{2}$ 中隐含了对“信息量”的提示。在本例中 $v$ 经过 $M$ 的转换投射到 $u$ 上时, $M$ 强调了在1方向上蕴含的信息。
现在再宽泛一些,如果我们能找到这样的一组 $v$ 和 $u$ ,并令 $\sigma$ 矩阵的值从大到小进行排列,那么我们不就能对 $M$ 进行拆解,同时在拆解过程中,找出 $M$ 所强调的那些特征方向了吗?也就是说:
$$
M = U\Sigma V^{T}
$$
当我们找到这样的 $U, \Sigma, V$ 矩阵后,我们再从这三者中取出对应的top r 行(或列),不就相当于关注到了 $M$ 最强调的那几维特征,进而就能用更低维的矩阵,来近似表达 $M$ 了?按这种思维拆解 $M$ 的方法,我们称为SVD分解(奇异值分解)。
我们再通过一个代码例子,更直观地感受一下这种近似,大家注意看下注释(例子改编自:LoRA: Low-Rank Adaptation from the first principle
1 | |
输出结果为:
1 | |
参数量变少了,但并不影响最终输出的结果。
2.2 让模型学习SVD分解的近似
从2.1中,我们知道SVD分解后,会将原矩阵 $M$ 拆成 $M = U\Sigma V^{T}$ 这样的形式,其中 $M$ 和 $V$ 都是正交矩阵,即满足 $M^{T}M= I, V^{T}V = I$ 。以 $M$ 为二维矩阵为例,这个SVD分解的式子长成下面这样:
$$
M = \begin{bmatrix}\vec{u_1}&\vec{u_2}\end{bmatrix}\begin{bmatrix}\sigma_1&0 \0&\sigma_2\end{bmatrix}\begin{bmatrix}\vec{v_1}\\vec{v_2}\end{bmatrix}
$$
LoRA的总体设计思想,是 $\Delta W = U \Sigma V^{T} \approx BA$ ,也就是让模型去学习两个矩阵A和B,用来近似SVD分解的结果,同时将A和B的秩都统一设成 $r$。
到了AdaLoRA这里,就有新方法了,我让模型去学习三个权重矩阵: $P, \Lambda, Q$ ,直接去近似 $\Delta W$ 真实的SVD分解结果,也就是 $\Delta W = U \Sigma V^{T} \approx P\Lambda Q$ ,这样也能达到目的。
2.3 AdaLoRA动态更新秩的过程
接下来,我们来仔细端详一下 $\Delta W = P \Lambda Q$ 。下图中描绘了AdaLoRA动态变秩的过程:
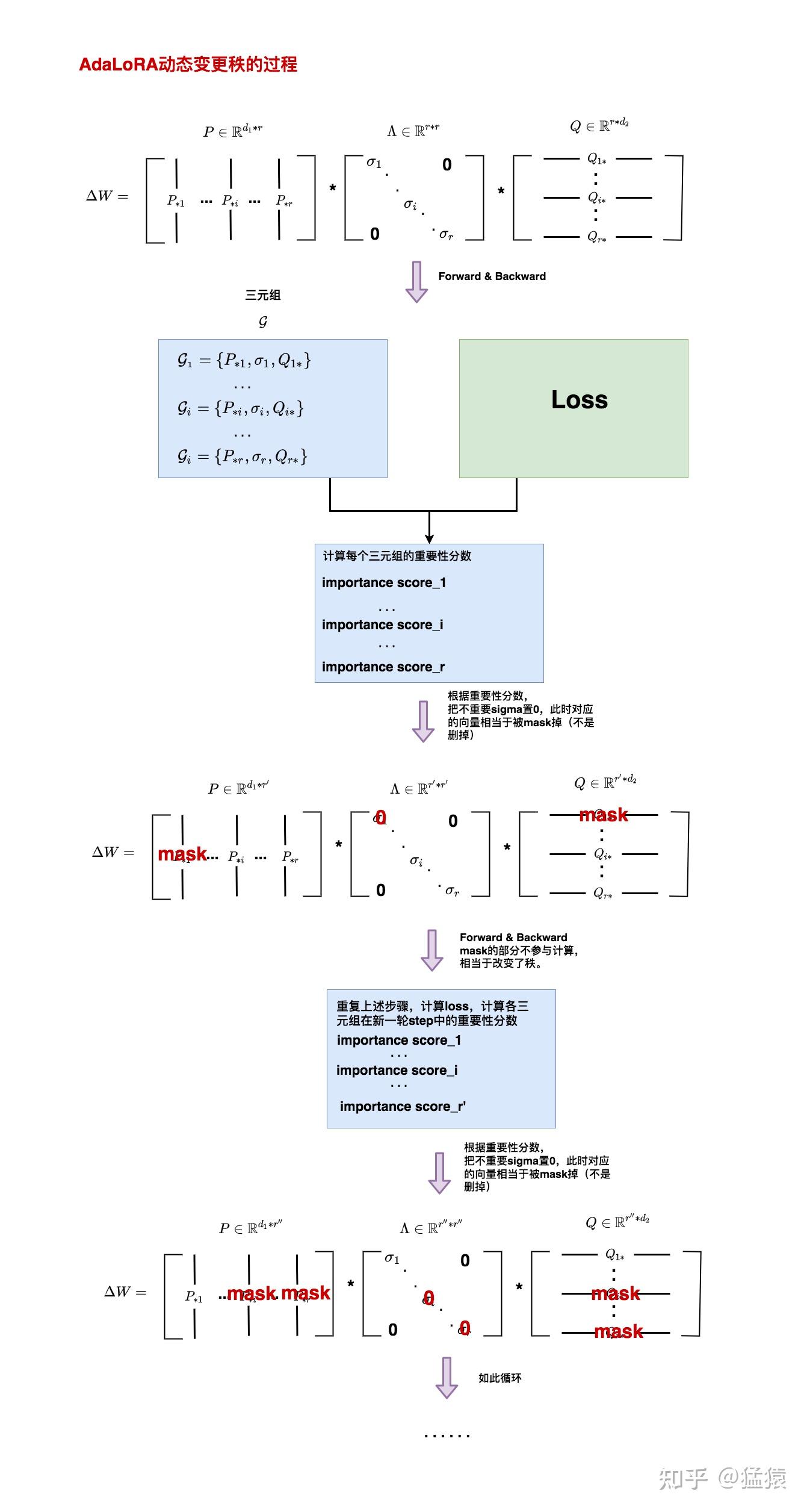
AdaLoRA变秩的整体流程如下:
(1)首先,我们初始化三个矩阵 $P, \Lambda, Q$ 。其中, $\Lambda$ 矩阵比较特殊,其大部分元素为0,只有对角线上的 $r$ 个元素有值。所以实操中我们可将其视为长度为 $r$ 的向量,即 $\Lambda \in \mathbb{R^{r}}$ 。初始化时,我们将 $\Lambda$ 初始化为0, $P, Q$ 初始化为高斯随机矩阵。这样做的目的和LoRA一样,都是为了在训练开始保证 $\Delta W$ 是0,以此避免引入噪声。
(2)然后,我们正常做forward和backward,得到Loss和参数的梯度。(Loss的设计我们在后文细说)
(3)接着,根据Loss和参数梯度,我们可以对图中所示的每个三元组(triplets) $\mathcal{G_{i}}{P_{i}, \sigma_{i}, Q_{i}}$ 计算重要性分数(importance scoring),其中, $P_{i}, Q_{i}$ 分别表示“第i列”和“第i行”。(重要性分数的计算方法我们在后文细说)
(4)接着,根据计算出来的重要性分数,我们将不重要的三元组挑选出来。(根据重要性分数筛选三元组的方法,我们在后文细说)。
(5)接着,对于不重要的三元组,我们将其 $\sigma$ 值置0。这样,在下一次做forward时,这个三元组里对应的 $P$ 向量和 $Q$ 向量相当于被mask掉了,对Loss没有贡献。也就起到了变秩的效果。
(6)接着,使用(2)中计算出来的梯度,更新 $P$ 和 $Q$ 的参数。
(7)然后,使用更新完毕的 $P, \Lambda, Q$ ,开启新一轮forward和backward,重复上面步骤,随时动态更新参数的秩。
需要特别说明的是,为什么在(5)中,我们只是将 $\sigma$ **置0,而不是把整个三元组删掉呢?**因为前面说过,模型的学习是一个探索的过程,在一开始模型认为不重要的三元组,在后续过程中模型可能会慢慢学到它的重要性。因此,mask是比删掉更合理的方法。也正是这个原因,我们在(6)中,不管三元组有没有被mask掉,我们都会正常用梯度更新 $P$ 和 $Q$ 。
好,理清了整体流程后,我们就可以来看细节了,在上述过程里,我们遗留了3个细节问题有待探讨:
- AdaLoRA中,Loss要怎么设计?
- AdaLoRA中,重要性分数要怎么算?
- AdaLoRA中,如何根据重要性分数筛选不重要的三元组,进而动态调整矩阵的秩?
我们来分别细看这三个问题。
三、AdaLoRA的Loss设计
在第二部分中,我们以某一模块的更新做了举例,但是在实际应用中,需要做AdaLoRA适配的模块肯定不止一个( $W_{q}, W_{k}, W_{v}, W_{o}, W_{f_{1}}…$ ),假设我们有n个模块需要做AdaLoRA适配,现在我们来严谨定义一些数学表达符号:
$\Delta_{k} = P_{k}\Lambda_{k}Q_{k}$ ,表示第k个需要做AdaLoRA适配的模块。其中 $k = 1, …, n$ ,n表示共有n个模块需要做AdaLoRA适配
$\mathcal{G_{k, i}} = {P_{k, i}, \lambda_{k, i}, Q_{k, i}}$ ,表示第k个模块的第i个三元组。注意上文中的 $\sigma$ 用 $\lambda$ 表示。(怪我,画完图才发现这个gap,但是不想改图了,大家能理解就行)
$S_{k, i}$ :表示第k个模块的第i个三元组的重要性分数。
$\mathcal{P} = {{P_{k}}^{n}_{k=1}}$ :表示所有n个模块的P矩阵的集合
$\mathcal{E} ={{\lambda_{k}}^{n}_{k=1}}$ :表示所有n个模块的 $\Lambda$ 矩阵的集合(实操中不是矩阵,是r维向量,前文说过)
$\mathcal{Q} = {{Q_{k}}^{n}_{k=1}}$ :表示所有n个模块的Q矩阵的集合
$\mathcal{C}(\mathcal{P}, \mathcal{E}, \mathcal{Q})$ :表示模型在训练集上的损失函数
$\mathcal{L}(\mathcal{P}, \mathcal{E}, \mathcal{Q})$ :表示模型最终的损失函数
细心的你可能已经发现了,这怎么有两个损失函数呢?那我们就直接来看最终损失函数的定义:
$$
\mathcal{L}(\mathcal{P}, \mathcal{E}, \mathcal{Q}) = \mathcal{C}(\mathcal{P}, \mathcal{E}, \mathcal{Q}) + \gamma \sum_{k=1}^{n} R(P_{k}, Q_{k}), \gamma > 0
$$
其中, $R(P, Q) = || P^{T}P- I||{F}^{2} + || Q^{T}Q - I||{F}^{2}$
$\mathcal{C}(\mathcal{P}, \mathcal{E}, \mathcal{Q})$ 好理解,它表示预测结果和真实标签间的差异。那后面那项又是什么呢?还记得我们在2.1中提过SVD分解相关的定义吗:$P$ 和 $Q$ 都必须是正交矩阵,即满足 $P^{T}P = I, Q^{T}Q = I$ 。
而在AdaLoRA中,我们是寄希望于模型学出的 $P,Q$ 能满足这个性质,所以在设计Loss时我们当然也要考虑它:当 $P$ 和 $Q$ 偏离这个性质太远时,我们在Loss中给予相应的惩罚, $\gamma$ 就是惩罚力度,也被称为正则项。
其实,这也是AdaLoRA相比于LoRA效果能更好的原因之一:LoRA中是让模型学习BA,去近似SVD分解的结果,但是在训练过程中,没有引入任何SVD分解相关的性质做约束,所以模型就可能学歪了(因此LoRA作者在文章中写了很多实验,证明学出来的BA在一定程度上能近似SVD分解,能取得较好的效果)。而AdaLoRA则是直接将这一束缚考虑到了Loss中。
四、AdaLoRA中的重要性分数
我们依然先明确几个数学表达:
- $S_{k, i}$ :表示第k个模块的第i个三元组的重要性分数。
- $\lambda_{k, i}$ :表示第k个模块的 $\Lambda$ 矩阵(再强调一下,实操中不是矩阵是向量)的第i个元素。
- $P_{k, ji}$ :表示第k个模块的P矩阵的第j行第i列个元素。
- $Q_{k, ij}$ :表示第k个模块的Q矩阵的第i行第j列个元素。
- $s(.)$ :表示计算单元素重要性的函数,我们在下文会细说。
- $\mathcal {L}$ :表示模型的损失函数。
4.1 单参数重要性分数
在开始正式讲重要性分数怎么算之前,我们先来看一个问题:到底什么是重要性分数?
我们在1.4中说过,AdaLoRA的整体目标是要做参数预算(budget),也就是忽略不重要的参数,然后把训练资源给重要的参数,在AdaLoRA中,我们是通过“变秩”来实现这种预算的动态分配的**。所以现在问题就变成:如何判断一个矩阵中的一个参数(我们将其表示为** $w_{ij}$ )对模型训练是否重要?
一个最直观的想法就是:去看看这个参数对Loss的影响。所以,在前人的研究中,就提出过**“梯度\参数”(gradient-weight product)**这种算法:
$$
I(w_{ij}) = |w_{ij}\bigtriangledown_{w_{ij}}\mathcal{L}|
$$
这种算法的设计思想非常直接:我去看看Loss在这个参数上的梯度,同时也考虑一下这个参数本身的大小,不就能综合判断出这个参数对模型的影响程度了吗?
4.2 改进:单参数重要性分数
4.1中的这个直观有效的想法,被广泛运用在前人做的参数剪枝的优化中,但它有一个显著的问题:我是在mini-batch上计算重要性分数的,不同step间重要性分数可能会受到mini-batch客观波动的影响,有啥办法能消除这种影响吗?
当然有啦,遇到这种消除波动的问题,我们肯定要祭出momentum 。
所以,AdaLoRA作者就提出了这样一种计算 $t$ 时刻,单个模型参数重要性的方法:
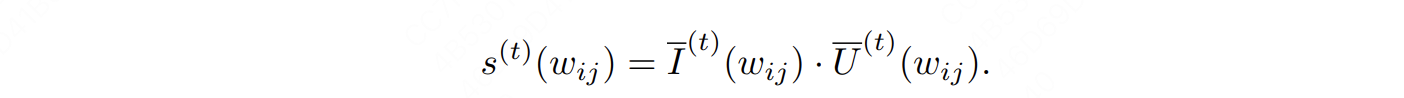
其中:
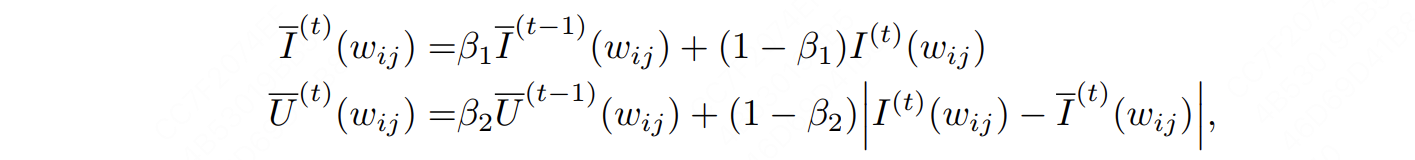
$ I^{(t)}(w_{ij})$ 表示根据4.1中的公式,计算出的t时刻的单参数重要性
$ \bar I^{(t)}(w_{ij}) $ 表示前t-1个时刻该单参数重要性的平滑值
$|I^{(t)}(w_{ij}) -\bar I^{(t)}(w_{ij}) |$ 表示当前值与平滑值之间的差异。这一项的意义是,你也不能一股脑地去平滑,也要考虑到重要性分数的真实波动情况
好,到这一步,我们就把计算单参数重要性分数的函数 $s^{(t)}(w_{ij})$ **讲清楚了!**知道了单参数的重要性分数,自然就可以知道整个三元组的重要性分数啦!
4.3 三元组重要性分数
在AdaLoRA中,三元组重要性分数计算方式如下:
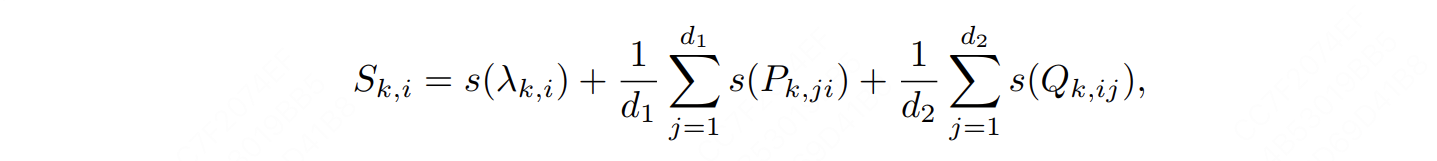
其中,小写的s就是我们在4.2中定义的单参数计算函数。
现在看这个公式,是不是很好理解呢:三元组的重要性分数 = $\lambda$ **的重要性分数 + P矩阵中所有元素重要性分数的均值 + Q矩阵中所有元素重要性分数的均值。**取均值的原因,是不希望参数量影响到重要性分数。
太好啦,到这一步为止,我们已经把AdaLoRA中难啃的Loss和三元组重要性分数讲完了,是不是比想象得简单很多?接下来我们来啃最后一块硬骨头:知道了三元组的重要性分数后,怎么动态调整矩阵的秩?
五、动态调整矩阵的秩
老规矩,在开始讲解前,我们再来明确几个数学符号:
- $\bigtriangledown_{P_{k}}\mathcal{L}(\mathcal{P}^{(t)}, \mathcal{E}^{(t)}, \mathcal{Q}^{(t)})$ :表示第 $k$ 个模块的P矩阵在 $t$ 时刻的梯度
- $ \bigtriangledown_{Q_{k}}\mathcal{L}(\mathcal{P}^{(t)}, \mathcal{E}^{(t)}, \mathcal{Q}^{(t)})$ :表示第 $k$ 个模块的Q矩阵在 $t$ 时刻的梯度
- $\bigtriangledown_{\Lambda_{k}}\mathcal{L}(\mathcal{P}^{(t)}, \mathcal{E}^{(t)}, \mathcal{Q}^{(t)})$ :表示第 $k$ 个模块的 $\Lambda$ 矩阵在 $t$ 时刻的梯度
5.1 调整函数
前文说过,动态调整矩阵秩的核心,就是根据三元组重要性分数,对 $\Lambda$ 矩阵中相应的 $\lambda$ 做置0处理。所以,我们就来看看 $\lambda$ 的置0策略。
(1)首先,我们拿 $ \bigtriangledown_{\Lambda_{k}}\mathcal{L}(\mathcal{P}^{(t)}, \mathcal{E}^{(t)}, \mathcal{Q}^{(t)})$ ,先更新一波 $\Lambda_{k}$ ,即我们有:
$$
\widetilde{\Lambda}{k}^{t} = \Lambda{k}^{t} - \eta \bigtriangledown_{\Lambda_{k}}\mathcal{L}(\mathcal{P}^{(t)}, \mathcal{E}^{(t)}, \mathcal{Q}^{(t)})
$$
其中, $\eta$ 是我们的学习率(learning_rate)
注意,这里 $\widetilde{\Lambda}_{k}^{t}$ 头上还顶着t时刻的标志,而不是t+1,也就是说,我们对 $\Lambda$ 做完梯度更新后的结果,并不是t+1时刻的结果。我们做完置0后,才是t+1时刻的结果。
(2)接着,我们按以下方式判断 $\Lambda$ 矩阵中哪些元素应该置0,哪些元素应该保持为梯度更新后的结果:
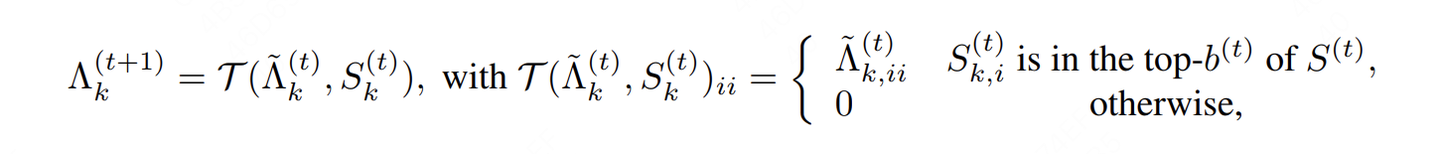
这个看起来很复杂的公式,表达的意思很简单:
- t+1时刻 $\Lambda$ 矩阵,是由 $\mathcal{T}$ 这个函数决定的,这个函数的输入是梯度更新后的 $\widetilde{\Lambda}{k}^{t}$ **,**以及第k个模块所有三元组的重要性分数 $S^{(t)}{k}$ .
- 那 $\mathcal{T}$ 这个函数具体就长成后面带大括号的那个样子。也就是重要性分数排在top_b的三元组,它们的 $\lambda$ 保持原样,其余的则置0
- 最后,这里的top_b也涉及一种策略,那就是它的值是随着t的变动而变化的(例如t=1时,我取的是top 2; t=2时,我取的是top b之类)。我们在下一小节细说这个策略
5.2 top_b策略
在开始讲top_b策略前,我们先来思考一个问题:为什么每次选出的重要三元组的个数,要随着时刻t的变动而变动?
这个问题的答案还是:模型的学习是探索性的过程。
在训练刚开始,我们逐渐增加top_b,也就是逐渐加秩,让模型尽可能多探索。到后期再慢慢把top_b降下来,直到最后以稳定的top_b进行训练,达到AdaLoRA的总目的:把训练资源留给最重要的参数。这个过程就和warm-up非常相似。
具体的策略在原始论文3.3节中有讲解,不难,所以我就不另外分析啦,大家可以自行阅读。以及本文的实验部分,我也不在这边写了,实验部分一句话总结就是相比LoRA确实有了不错的提升,大家可以自己去看细节。
六、AdaLoRA训练流程总结(必看)
最后,我们把AdaLoRA的整体训练流程总结一下:
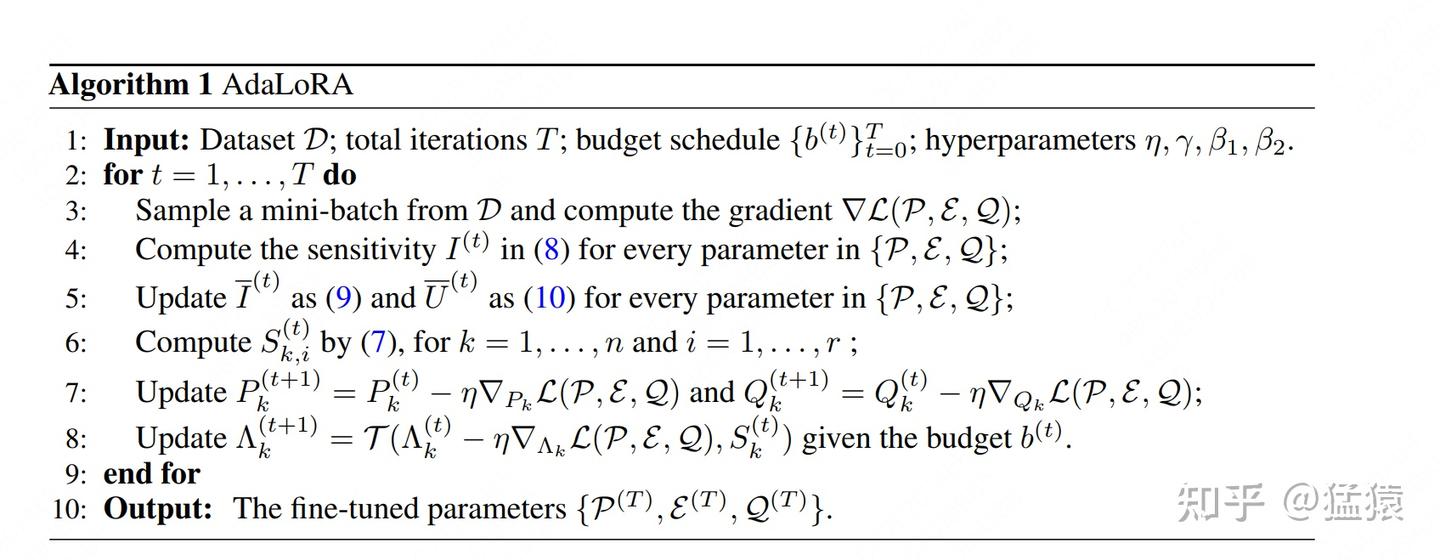
(1)拿到训练数据集,确定好总训练步长T。根据总步长T设计好top_b的warm-up策略,并设定好一系列超参,同时也把 $P, \Lambda, Q$ 的初始化做好
(2)进入某个step的迭代
(3)给模型喂一份mini-batch,正常做forward和backward,计算loss和梯度
(4)(5)对某一个三元组,我们先计算其中每个参数的重要性(单参数重要性)
(6)根据单参数重要性,计算出整个三元组的重要性分数
(7)使用(3)中计算好的梯度,正常更新矩阵P和Q
(8)根据三元组重要性分数、动态调秩策略、top_b来判断要给哪些 $\lambda$ 置0,其对应的三元组中的P和Q向量相当于被mask掉,以此来实现动态调秩的目的。这番操作后,我们得到更新的矩阵 $\Lambda$ 然后将 $P, \Lambda, Q$ 送入下一轮训练。
以此类推。
七、参考



