
LoRA-Pro
文章解读
“LoRA-GA”通过梯度SVD来改进LoRA的初始化,从而实现LoRA与全量微调的对齐。当然,从理论上来讲,这样做也只能尽量对齐第一步更新后的$W_1$,LoRA-Pro同样是想着对齐全量微调,但它对齐的是每一步梯度,从而对齐整条优化轨迹,这正好是跟LoRA-GA互补的改进点。
对齐全量
LoRA的参数化方式是
$$W = (W_0 - A_0 B_0) + AB\tag{1}$$
其中$W_0 \in \mathbb{R}^{n\times m}$ 预训练权重,$A\in\mathbb{R}^{n\times r},B\in\mathbb{R}^{r\times m}$ 新引入的训练参数,$A_0,B_0$ 它们的初始化值。 上一节我们说到,全量微调很多时候效果都优于LoRA,所以全量微调就是LoRA最应该对齐的方向。为了定量描述这一点,我们分别写出全量微调和LoRA微调在SGD下的优化公式,结果分别是
$$ W_{t+1} = W_t - \eta G_t\tag{2}$$
和
$$\begin{gathered} A_{t+1} = A_t - \eta G_{A,t} = A_t - \eta G_t B_t^{\top},\quad B_{t+1} = B_t - \eta G_{B,t} = B_t - \eta A_t^{\top}G_t \[8pt] W_{t+1} = W_t - A_t B_t + A_{t+1} B_{t+1} \approx W_t - \eta(A_t A_t^{\top}G_t + G_tB_t^{\top} B_t) \end{gathered}\tag{3}$$
其中$\mathcal{L}$ 损失函数,$\eta$ 学习率,还有$G_t=\frac{\partial \mathcal{L}}{\partial W_t}$、$G_{A,t}=\frac{\partial \mathcal{L}}{\partial A_t}=\frac{\partial \mathcal{L}}{\partial W_t} B_t^{\top}=G_t B_t^{\top}$ 及$G_{B,t}=\frac{\partial \mathcal{L}}{\partial B_t}=A_t^{\top}\frac{\partial \mathcal{L}}{\partial W_t} =A_t^{\top}G_t$。
LoRA-GA的想法是,我们至少要让全量微调和LoRA的$W_1$ 可能相近,于是它最小化目标
$$\mathop{\text{argmin}}_{A_0,B_0}\left\Vert A_0 A_0^{\top}G_0 + G_0 B_0^{\top} B_0 - G_0\right\Vert_F^2 \tag{4}$$
其最优解可以通过对$G_0$ 行SVD求得,这样我们就可以求出最优的$A_0,B_0$ 为$A,B$ 初始化。
逐步对齐
LoRA-Pro的想法更彻底,它希望对齐全量微调和LoRA的每一个$W_t$。可是要怎样才能做到这一点呢?难道每一步都要最小化$\left\Vert A_t A_t^{\top}G_t + G_t B_t^{\top} B_t - G_t\right\Vert_F^2$ ? 这显然是不对的,因为$A_t,B_t$ 由优化器根据$A_{t-1},B_{t-1}$ 它们的梯度确定的,并不是可自由调节的参数。
看上去已经没有能够让我们修改的地方了?不,LoRA-Pro非常机智地想到:既然“$A_t,B_t$ 由优化器根据$A_{t-1},B_{t-1}$ 它们的梯度确定的”,后面的$A_{t-1},B_{t-1}$ 梯度我们都没法改,那我们还可以改优化器呀!具体来说,我们将$A_t,B_t$ 更新规则改为:
$$\begin{gathered} A_{t+1} = A_t - \eta H_{A,t} \ B_{t+1} = B_t - \eta H_{B,t} \end{gathered}\tag{5}$$
其中$H_{A,t},H_{B,t}$ 定,但它们的形状跟$A,B$ 致。现在可以写出
$$W_{t+1} = W_t - A_t B_t + A_{t+1} B_{t+1} \approx W_t - \eta(H_{A,t} B_t + A_t H_{B,t}) \tag{6}$$
这时候我们就可以调整$H_{A,t},H_{B,t}$,让这个$W_{t+1}$ SGD的$W_{t+1}$ 可能相近了:
$$\mathop{\text{argmin}}{H{A,t},H_{B,t}}\left\Vert H_{A,t} B_t + A_t H_{B,t} - G_t\right\Vert_F^2 \tag{7}$$
下面我们来求解这个优化问题。简单起见,在求解过程中我们省略下标$t$,即考虑
$$\mathop{\text{argmin}}_{H_A,H_B}\left\Vert H_A B + A H_B - G\right\Vert_F^2\tag{8}$$
简化目标
由于$H_A,H_B$ 间没有约束,所以$H_A,H_B$ 优化是独立的,因此我们可以采取先优化$H_A$ 优化$H_B$ 策略(当然反过来也可以)。当我们优化$H_A$ ,$H_B$ 相当于是常数,为此,我们可以先考虑如下简化的等价命题
$$\mathop{\text{argmin}}_H\left\Vert H B - X\right\Vert_F^2 \tag{9}$$
其中$H\in\mathbb{R}^{n\times r},B\in\mathbb{R}^{r\times m},X\in\mathbb{R}^{n\times m}$。如果$r=m$ $B$ 逆,那么我们直接可以变为解方程组$HB=X$,即$H=XB^{-1}$。当$r < m$ ,我们就要诉诸优化手段,注意到$HB-X$ 于$H$ 线性的,所以这实质就是线性回归的最小二乘问题,它是有解析解的,答案是
$$H = XB^{\top}(B B^{\top})^{-1} \tag{10}$$
其中$B^{\top}(B B^{\top})^{-1}$ 是矩阵$B$ “伪逆”。不了解这个答案也不要紧,我们现场推一下。首先,记$\mathcal{l}=\left\Vert H B - X\right\Vert_F^2$,直接求$H$ 导数得到
$$\frac{\partial l}{\partial H} = 2(HB - X)B^{\top} = 2(HBB^{\top} - XB^{\top}) \tag{11}$$
然后让它等于零就可以解出式$(10)$。可能有些读者不大了解矩阵求导法则,其实根据求导的链式法则,我们就不难想到$\frac{\partial l}{\partial H}$ $2(HB - X)$ $B$ 某种方式相乘起来,然后我们约定$\frac{\partial l}{\partial H}$ 形状跟$H$ 样,即$n\times r$,那么由$2(HB - X)$ $B$ 乘来凑出一个$n\times r$ 结果,也只有$2(HB - X)B^{\top}$ 。
同理,$\left\Vert AH - X\right\Vert_F^2$ $H$ 导数就是$2A^{\top}(AH - X)$,由此可以得到
$$\mathop{\text{argmin}}_H\left\Vert AH - X\right\Vert_F^2\quad\Rightarrow\quad H = (A^{\top} A)^{-1}A^{\top}X \tag{12}$$
完整结果
有了结论$(10)$ $(12)$,我们就可以着手求解$(8)$ 。首先我们固定$H_B$,那么根据式$(10)$ 到
$$H_A = (G - A H_B) B^{\top}(B B^{\top})^{-1}\tag{13}$$
注意式$(8)$ 目标函数具有一个不变性:
$$\left\Vert H_A B + A H_B - G\right\Vert_F^2 = \left\Vert (H_A + AC) B + A (H_B - CB) - G\right\Vert_F^2 \tag{14}$$
其中$C$ 任意$r\times r$ 矩阵。也就是说,$H_A$ 解可以加/减任意具有$AC$ 式的矩阵,只需要$H_B$ /加对应的$CB$ 行。根据该性质,我们可以将式$(13)$ $H_A$ 化成
$$H_A = G B^{\top}(B B^{\top})^{-1} \tag{15}$$
代回目标函数得
$$\mathop{\text{argmin}}_{H_B}\left\Vert A H_B - G(I - B^{\top}(B B^{\top})^{-1}B)\right\Vert_F^2 \tag{16}$$
根据式$(12)$
$$H_B = (A^{\top} A)^{-1}A^{\top}G(I - B^{\top}(B B^{\top})^{-1}B) \tag{17}$$
留意到$G B^{\top},A^{\top}G$ 好分别是$A,B$ 梯度$G_A,G_B$,以及再次利用前述不变性,我们可以写出完整的解
$$\left{\begin{aligned} H_A =&, G_A (B B^{\top})^{-1} + AC \ H_B =&, (A^{\top} A)^{-1}G_B(I - B^{\top}(B B^{\top})^{-1}B) - CB \end{aligned}\right.\tag{18}$$
最优参数
至此,我们求解出了$H_A,H_B$ 形式,但解不是唯一的,它有一个可以自由选择的参数矩阵$C$。我们可以选择适当的$C$,来使得最终的$H_A,H_B$ 备一些我们所期望的特性。
比如,现在$H_A,H_B$ 不大对称的,$H_B$ 了$-(A^{\top} A)^{-1}G_B B^{\top}(B B^{\top})^{-1}B$ 一项,我们可以将它平均分配到$H_A,H_B$ ,使得它们更对称一些,这等价于选择$C = -\frac{1}{2}(A^{\top} A)^{-1}G_B B^{\top}(B B^{\top})^{-1}$:
$$\left{\begin{aligned} H_A =&, \left[I - \frac{1}{2}A(A^{\top}A)^{-1}A^{\top}\right]G_A (B B^{\top})^{-1} \ H_B =&, (A^{\top} A)^{-1}G_B\left[I - \frac{1}{2}B^{\top}(B B^{\top})^{-1}B\right] \end{aligned}\right.\tag{19}$$
这个$C$ 是如下两个优化问题的解:
$$\begin{align} \mathop{\text{argmin}}_C \Vert H_A B - A H_B\Vert_F^2\end{align} \tag{20}$$
$$ \begin{align}\mathop{\text{argmin}}_C \Vert H_A B - G\Vert_F^2 + \Vert A H_B - G\Vert_F^2 \ \end{align}\tag{21}$$
第一个优化目标可以理解为让$A,B$ 最终效果的贡献尽可能一样,这跟《配置不同的学习率,LoRA还能再涨一点?》的假设有一定异曲同工之处,第二个优化目标则是让$H_A B$、$A H_B$ 尽可能逼近完整的梯度$G$。以$l=\Vert H_A B - A H_B\Vert_F^2$ 例,直接求导得
$$\frac{\partial l}{\partial C} = 4A^{\top}(H_A B - A H_B)B^{\top}=4A^{\top}\left[G_A (BB^{\top})^{-1}B + 2ACB\right]B^{\top} \tag{22}$$
令它等于零我们就可以解出同样的$C$,化简过程比较关键的两步是$[I - B^{\top}(B B^{\top})^{-1}B]B^{\top} = 0$ 及$A^{\top}G_A = G_B B^{\top}$。
LoRA-Pro选择的$C$ 有不同,它是如下目标函数的最优解
$$\mathop{\text{argmin}}_C \Vert H_A - G_A\Vert_F^2 + \Vert H_B - G_B\Vert_F^2 \tag{23}$$
这样做的意图也很明显:$H_A,H_B$ 用来取代$G_A,G_B$ ,如果在能达到相同效果的前提下,相比$G_A,G_B$ 改动尽可能小,不失为一个合理的选择。同样求$C$ 导数并让其等于零,化简可得
$$A^{\top}A C + C B B^{\top} = -A^{\top} G_A (BB^{\top})^{-1} \tag{24}$$
现在我们得到关于$C$ 一个方程,该类型的方程叫做“Sylvester方程”,可以通过外积符号写出$C$ 解析解,但没有必要,因为直接数值求解的复杂度比解析解的复杂度要低,所以直接数值求解即可。总的来说,这些$C$ 选择方案,都是在让$H_A,H_B$ 某种视角下更加对称一些,虽然笔者没有亲自做过对比实验,但笔者认为这些不同的选择之间不会有太明显的区别。
一般讨论
我们来捋一捋到目前为止我们所得到的结果。我们的模型还是常规的LoRA,目标则是希望每一步更新都能逼近全量微调的结果。为此,我们假设优化器是SGD,然后对比了同样$W_t$ 全量微调和LoRA所得的$W_{t+1}$,发现要实现这个目标,需要把更新过程中$A,B$ 梯度$G_A, G_B$ 成上面求出的$H_A,H_B$。
接下来就又回到优化分析中老生常谈的问题:前面的分析都是基于SGD优化器的,但实践中我们更常用的是Adam,此时要怎么改呢?如果对Adam优化器重复前面的推导,结果就是$H_A,H_B$ 的梯度$G$ 换成全量微调下Adam的更新方向$U$。然而,$U$ 要用全量微调的梯度$G$ 照Adam的更新规则计算而来,而我们的场景是LoRA,无法获得全量微调的梯度,只有$A,B$ 梯度$G_A,G_B$。
不过我们也可以考虑一个近似的方案,前述$H_A B + A H_B$ 优化目标就是在逼近$G$,所以我们可以用它来作为$G$ 近似来执行Adam,这样一来整个流程就可以走通了。于是我们可以写出如下更新规则
$$\begin{array}{l} \begin{array}{l}G_A = \frac{\partial\mathcal{L}}{\partial A_{t-1}},,,G_B = \frac{\partial\mathcal{L}}{\partial B_{t-1}}\end{array} \ \color{green}{\left.\begin{array}{l}H_A = G_A (B B^{\top})^{-1} \ H_B = (A^{\top} A)^{-1}G_B(I - B^{\top}(B B^{\top})^{-1}B) \ \tilde{G} = H_A B + A H_B \end{array}\quad\right} \text{估计梯度}} \ \color{red}{\left.\begin{array}{l}M_t = \beta_1 M_{t-1} + (1 - \beta_1) \tilde{G} \ V_t = \beta_2 V_{t-1} + (1 - \beta_2) \tilde{G}^2 \ \hat{M}_t = \frac{M_t}{1-\beta_1^t},,,\hat{V}_t = \frac{V_t}{1-\beta_2^t},,,U = \frac{\hat{M}_t}{\sqrt{\hat{V}_t + \epsilon}}\end{array}\quad\right} \text{Adam更新}} \ \color{purple}{\left.\begin{array}{l}U_A = UB^{\top},,, U_B = A^{\top} U \ \tilde{H}_A = U_A (B B^{\top})^{-1} + AC \ \tilde{H}B = (A^{\top} A)^{-1}U_B(I - B^{\top}(B B^{\top})^{-1}B) - CB \end{array}\quad\right} \text{投影到}A,B} \ \begin{array}{l}A_t = A{t-1} - \eta \tilde{H}A \ B_t = B{t-1} - \eta \tilde{H}_B \ \end{array} \ \end{array}\tag{25}$$
这也是LoRA-Pro最终所用的更新算法(更准确地说,LoRA-Pro用的是AdamW,结果稍复杂一些,但并无实质不同)。然而,且不说如此改动引入的额外复杂度如何,这个算法最大的问题就是它里边的滑动更新变量$M,V$ 全量微调一样都是满秩的,也就是说它的优化器相比全量微调并不省显存,仅仅是通过低秩分解节省了参数和梯度的部分显存,这相比常规LoRA的显存消耗还是会有明显增加的。
一个比较简单的方案(但笔者没有实验过)就是直接用$H_A,H_B$ 代$G_A,G_B$,然后按照常规LoRA的Adam更新规则来计算,这样$M,V$ 形状就跟相应的$A,B$ 致了,节省的显存达到了最大化。不过此时的Adam理论基础不如LoRA-Pro的Adam,更多的是跟《对齐全量微调!这是我看过最精彩的LoRA(一)》一样,靠“SGD的结论可以平行应用到Adam”的信仰来支撑。
实验结果
LoRA-Pro在GLUE上的实验结果更加惊艳,超过了全量微调的结果:
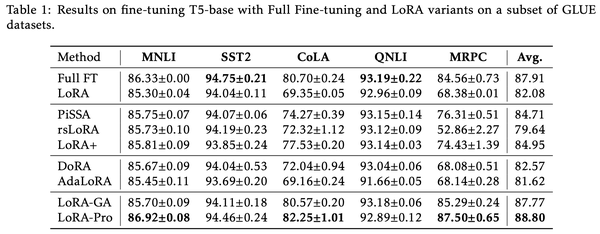
不过论文也就只有这个实验了。看上去LoRA-Pro成文比较仓促,可能是看到LoRA-GA后觉得“撞车”感太明显,所以先赶出来占个坑吧。笔者刚刷到LoRA-Pro时,第一反应也是跟LoRA-GA撞车了,但仔细阅读之下才发现,它跟LoRA-GA实际上是同一思想下互补的结果。
从LoRA-Pro的结果来看,它包含了$A^{\top} A$ $B B^{\top}$ 求逆,所以很明显$A,B$ 一就不能用全零初始化了,比较符合直觉的正交初始化,即让初始的$A^{\top} A,B B^{\top}$ 单位阵(的若干倍)。刚好从《对齐全量微调!这是我看过最精彩的LoRA(一)》我们可以看到,LoRA-GA给出的初始化正好是正交初始化,所以LoRA-Pro跟LoRA-GA可谓是“最佳搭档”了。
文章小结
本文介绍了另一个对齐全量微调的工作LoRA-Pro,它跟上一篇的LoRA-GA正好是互补的两个结果,LoRA-GA试图通过改进初始化来使得LoRA跟全量微调对齐,LoRA-Pro则更彻底一些,它通过修改优化器的更新规则来使得LoRA的每一步更新都尽量跟全量微调对齐,两者都是非常精彩的LoRA改进,都是让人赏心悦目之作。



