
不平衡类增量学习综述
CVPR2024 GR
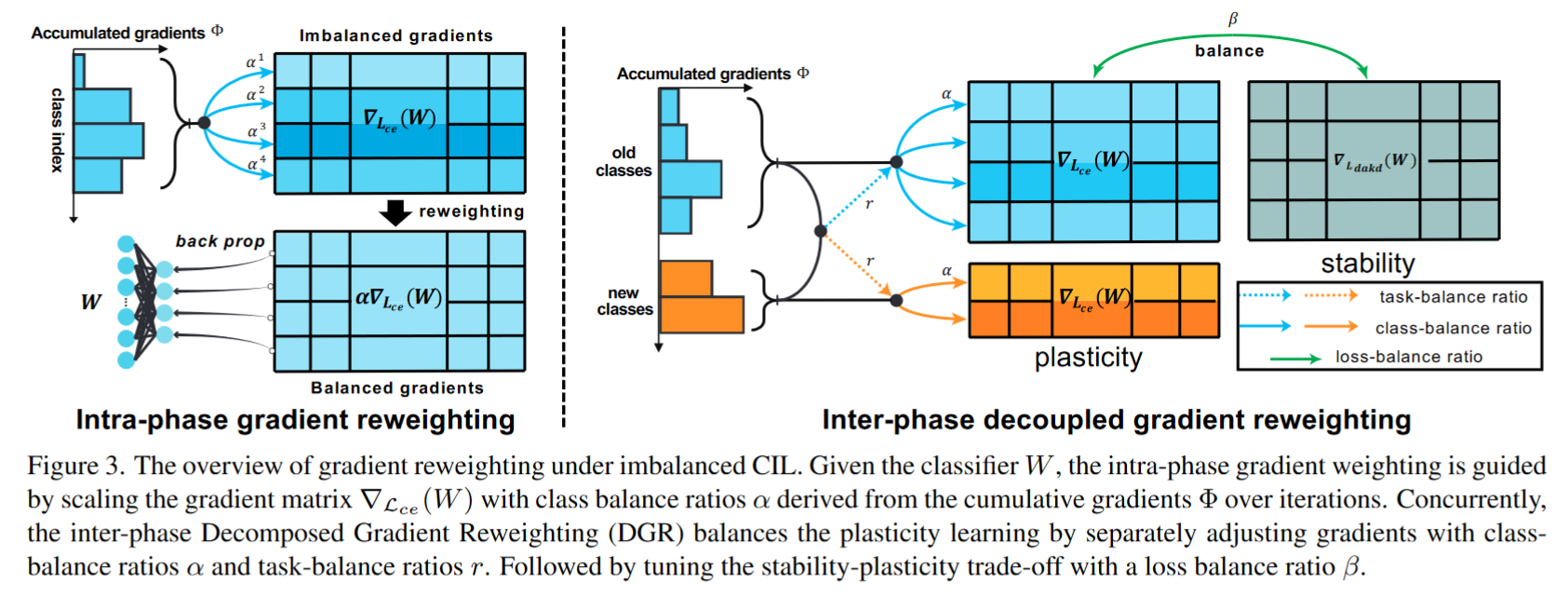
Gradient Reweighting: Towards Imbalanced Class-Incremental Learning
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Hongwei Zhao's Blog!
相关推荐

2025-11-16
Architecture Matters in Continual Learning
0. 摘要在持续学习(Continual Learning)领域,大量研究致力于通过设计能够应对分布变化的新算法,来克服神经网络的灾难性遗忘问题。然而,这些研究大多仅专注于为“固定的神经网络架构”开发新的算法,并在很大程度上忽略了使用不同架构的影响。即便是少数修改模型的持续学习方法,也假定架构固定,并试图开发一种算法以在整个学习过程中高效利用该模型。 在这项工作中,我们展示了架构选择会显著影响持续学习的性能,不同架构在记住先前任务和学习新任务的能力之间存在不同的权衡。此外,我们研究了各种架构决策的影响,并提出了一些最佳实践和建议,可以改善持续学习的性能。 1. 引言持续学习(C...

2025-11-16
Parameter-Efficient Fine-Tuning Methods for Pretrained Language Models A Critical Review and Assessment
0 摘要随着基于 Transformer 的预训练语言模型(PLMs)参数数量的不断增长,特别是具有数十亿参数的大型语言模型(LLMs)的出现,许多自然语言处理(NLP)任务展示出了显著的成功。然而,这些模型的巨大规模和计算需求对其适应特定下游任务提出了重大挑战,尤其是在计算资源有限的环境中。参数高效微调(PEFT)通过减少微调参数数量和内存使用量,同时实现与完全微调相当的性能,提供了一种有效的解决方案。对 PLMs,特别是 LLMs 的微调需求导致了 PEFT 方法的快速发展,如图 1 所示。在本文中,我们对 PLMs 的 PEFT 方法进行了全面和系统的回顾。我们总结了这些 PEFT...

2025-11-16
无监督类增量学习
半监督增量学习首先,让我们先学习下半监督式的增量学习,其旨在通过利用未标记的数据来减少对标签的依赖。常规的做法是先利用一小部分带有标签的数据集训练出一个深度学习模型,然后利用该模型对未标记的数据打上标签。通常,我们将这种用非人工标注的标签信息称之为——伪标签(pseudo labels)。 因此,根据未标记数据的类型,我们可以简单的划分为三种类型: Within-data,即属于同一份数据集内的没有打标签的那部分数据; Auxiliary-data,即辅助数据,例如大家从网络上爬下来的数据; Test-data,即最简单的测试集数据 其中,Within-data 需要模型从头开始训练...

2025-11-16
多模态类增量学习
2025-11-16
Continual Learning With Knowledge Distillation A Survey
0. 摘要持续学习中的首要挑战是缓解灾难性遗忘,使模型在学习新任务的同时保留对先前任务的知识。知识蒸馏(KD)作为一种正则化方法,因其在学习新任务时通过模仿早期模型的输出来保持模型在先前任务上的性能而受到广泛关注,从而减少遗忘。本文对图像分类领域中采用 KD 的持续学习方法进行了全面调查。我们详细分析了 KD 在持续学习方法中的应用,并将其应用分为三种不同的范式。此外,我们根据所使用的知识源类型对这些方法进行了分类,并从损失函数的角度深入探讨了 KD 如何巩固持续学习中的记忆。我们还通过在 CIFAR-100、TinyImageNet 和 ImageNet-100 数据集上对十种集成 K...
2025-11-16
类增量学习综述
基于 Class-Incremental Learning: A Survey Data Data Replay Direct Replay Generative Replay Data Regularization 基于回放的增量学习的基本思想就是”温故而知新”,在训练新任务时,一部分具有代表性的旧数据会被保留并用于模型复习曾经学到的旧知识,因此要保留旧任务的哪部分数据,以及如何利用旧数据与新数据一起训练模型,就是这类方法需要考虑的主要问题。 Direct ReplayGenerative ReplayData RegularizationModel Dyna...